适用于版本0.10.1。
1 DeltaStreamer
能力:
- 刚好一次消费保证,Kafka、Scoop增量导入、HiveIncrementalPuller输出、DFS文件
- 支持多种来源记录类型,如json、avro和自定义类型
- 支持管理检查点、回退和恢复
- 利用DFS中的avro模式或融合模式注册
- 支持插件转换
详细能力支持详见命令行帮助:
1 | [hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` --help |
Kafka、dfs配置示例详见hudi-utilities/src/test/resources/delta-streamer-config。
示例:
使用Confluent Kafkashi使用avro文件模式注册并产生测试数据。
1 | [confluent-5.0.0]$ bin/ksql-datagen schema=../impressions.avro format=avro topic=impressions key=impressionid |
消费数据:
1 | [hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` \ |
提前迁移表至Hudi,详见迁移指南。
(1) 多表DeltaStreamer
HoodieMultiTableDeltaStreamer是包装后的HoodieDeltaStreamer,用于消费数据到多张表中。
当前仅支持顺序消费和COW类型。
与HoodieDeltaStreamer不同的是,需要为不同的表单独配置。
示例配置详见hudi-utilities/src/test/resources/delta-streamer-config
详情参照博客
1 | * --config-folder |
(2) 并发控制
OCC示例,如需要配置kafka-source.properties
1 | [hoodie]$ spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer `ls packaging/hudi-utilities-bundle/target/hudi-utilities-bundle-*.jar` \ |
2 检查点
使用检查点记录上次消费的数据位置。Kafka数据源使用Kafka Offset记录,DFS数据源使用最新文件的最近修改时间。数据记录在.hoodie文件中的deltastreamer.checkpoint.key。
修改检查点的方式:
–checkpoint
将修改deltastreamer.checkpoint.reset_key以覆盖检查点
–source-limit
设置读取的最大数据量。DFS数据源单位为字节,Kafka数据源单位为事件数量。
3 模式推断
默认Spark可以从数据源中推断模式。同时也可以通过以下方式显式定义。
(1) 在线注册
可以通过在线注册的方式获取最新模式。
spark-submit配置形如–hoodie-conf hoodie.deltastreamer.schemaprovider.registry.url=https://foo:bar@schemaregistry.org
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.registry.url | The schema of the source you are reading from | https://foo:[bar@schemaregistry.org](mailto:bar@schemaregistry.org) |
| hoodie.deltastreamer.schemaprovider.registry.targetUrl | The schema of the target you are writing to | https://foo:[bar@schemaregistry.org](mailto:bar@schemaregistry.org) |
(2) JDBC方式
spark-submit配置形如–hoodie-conf hoodie.deltastreamer.jdbcbasedschemaprovider.connection.url=jdbc:postgresql://localhost/test?user=fred&password=secret
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.connection.url | The JDBC URL to connect to. You can specify source specific connection properties in the URL | jdbc:postgresql://localhost/test?user=fred&password=secret |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.driver.type | The class name of the JDBC driver to use to connect to this URL | org.h2.Driver |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.username | username for the connection | fred |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.password | password for the connection | secret |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.dbtable | The table with the schema to reference | test_database.test1_table or test1_table |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.timeout | The number of seconds the driver will wait for a Statement object to execute to the given number of seconds. Zero means there is no limit. In the write path, this option depends on how JDBC drivers implement the API setQueryTimeout, e.g., the h2 JDBC driver checks the timeout of each query instead of an entire JDBC batch. It defaults to 0. | 0 |
| hoodie.deltastreamer.schemaprovider.source.schema.jdbc.nullable | If true, all columns are nullable | true |
(3)文件方式
定义.avsc文件
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.schemaprovider.source.schema.file | The schema of the source you are reading from | example schema file |
| hoodie.deltastreamer.schemaprovider.target.schema.file | The schema of the target you are writing to | example schema file |
(4) Post Processor方式
从以上方式中选择一个用于获取模式,需要实现SchemaPostProcessor
4 来源
(1) DFS
支持以下数据格式:
- CSV
- AVRO
- JSON
- PARQUET
- ORC
- HUDI
(2) Kafka
可以直接从kafka集群读取数据,刚好一次语义、检查点和插件转换详见HoodieDeltaStreamer。
支持以下数据格式:
- AVRO
- JSON
(3) S3事件
略
(4) JDBC
可以整个读取表,或者基于检查点增量读取。
| Config | Description | Example |
|---|---|---|
| hoodie.deltastreamer.jdbc.url | URL of the JDBC connection | jdbc:postgresql://localhost/test |
| hoodie.deltastreamer.jdbc.user | User to use for authentication of the JDBC connection | fred |
| hoodie.deltastreamer.jdbc.password | Password to use for authentication of the JDBC connection | secret |
| hoodie.deltastreamer.jdbc.password.file | If you prefer to use a password file for the connection | |
| hoodie.deltastreamer.jdbc.driver.class | Driver class to use for the JDBC connection | |
| hoodie.deltastreamer.jdbc.table.name | my_table | |
| hoodie.deltastreamer.jdbc.table.incr.column.name | If run in incremental mode, this field will be used to pull new data incrementally | |
| hoodie.deltastreamer.jdbc.incr.pull | Will the JDBC connection perform an incremental pull? | |
| hoodie.deltastreamer.jdbc.extra.options. | How you pass extra configurations that would normally by specified as spark.read.option() | hoodie.deltastreamer.jdbc.extra.options.fetchSize=100 hoodie.deltastreamer.jdbc.extra.options.upperBound=1 hoodie.deltastreamer.jdbc.extra.options.lowerBound=100 |
| hoodie.deltastreamer.jdbc.storage.level | Used to control the persistence level | Default = MEMORY_AND_DISK_SER |
| hoodie.deltastreamer.jdbc.incr.fallback.to.full.fetch | Boolean which if set true makes an incremental fetch fallback to a full fetch if there is any error in the incremental read | FALSE |
(5) SQL
SQL数据源主要用于填充指定分区的数据,不会更新deltastreamer.checkpoint.key,而是设置为最近成功提交的检查点。
为了获取并使用最近增量检查点,需要设置hoodie.write.meta.key.prefixes = 'deltastreamer.checkpoint.key'。
Spark SQL需要设置hoodie.deltastreamer.source.sql.sql.query = 'select * from source_table'。
5 Flink消费
(1) CDC消费
Change Data Capture用于跟踪数据源的变化。推荐使用以下两种方式:
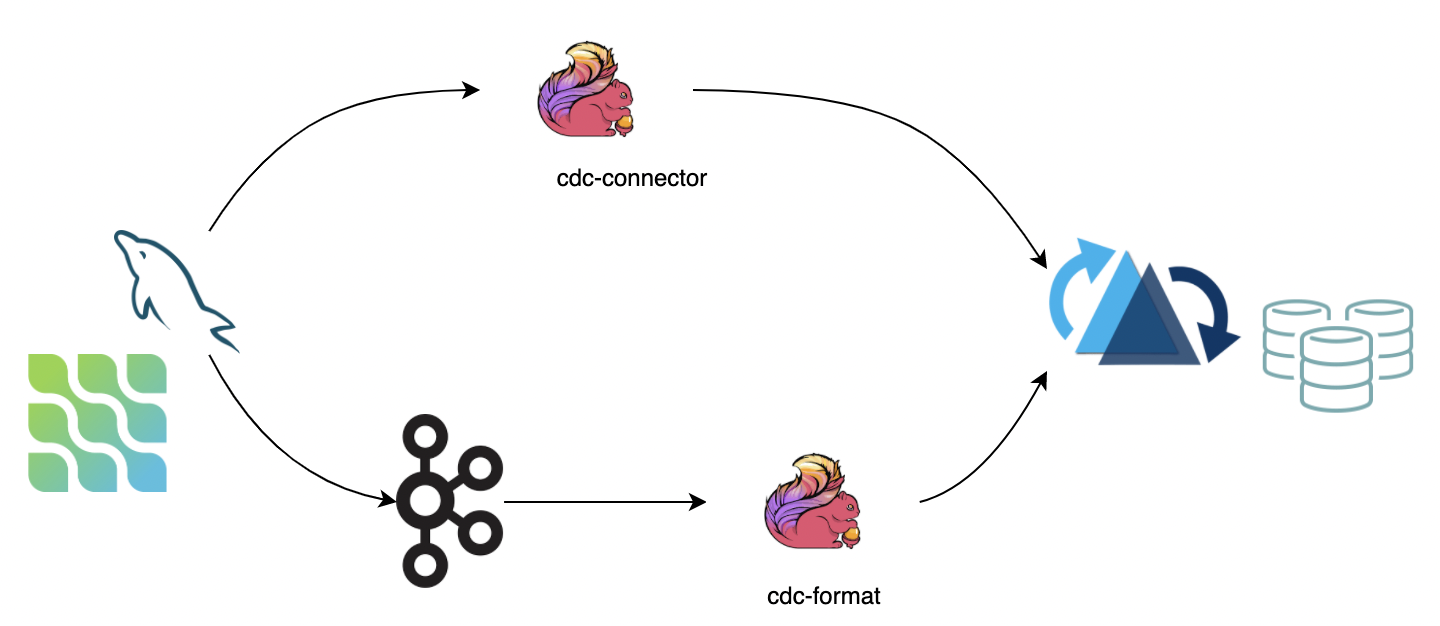
- 使用flink-cdc-connectors直接连接数据库并同步binlog到Hudi。优点是不需要消息队列,缺点是增加数据库负载。
- 使用flink cdc format格式从消息队列消费。优点是高可扩展,缺点是依赖消息队列。
注意:
- 如果上游数据无法保证有序,需要显式设置
write.precombine.field。 - 当前MOR表在事件时间序列中无法删除,会导致数据丢失。最好转换为changelog模式
changelog.enabled。
(2) 批量插入
使用批量插入导入快照数据。
注意:
- 批量插入忽略了序列化和数据合并,需要自行保证数据唯一性。
- 在批量执行模式中批量插入更有效率。默认批量执行模式按分区路径排序,避免频繁文件操作导致的写性能下降。
- 批量插入的并发由
write.tasks配置。并发度影响小文件的数量。理论上,批量插入的并发度是bucket的数量,但当bucket写满时,会新增文件,因此文件数量不小于write.bucket_assign.tasks
配置
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.operation |
true |
upsert |
Setting as bulk_insert to open this function |
write.tasks |
false |
4 |
The parallelism of bulk_insert, the number of files >= write.bucket_assign.tasks |
write.bulk_insert.shuffle_by_partition |
false |
true |
Whether to shuffle data according to the partition field before writing. Enabling this option will reduce the number of small files, but there may be a risk of data skew |
write.bulk_insert.sort_by_partition |
false |
true |
Whether to sort data according to the partition field before writing. Enabling this option will reduce the number of small files when a write task writes multiple partitions |
write.sort.memory |
false |
128 |
Available managed memory of sort operator. default 128 MB |
(3) 索引引导
在导入快照数据后,可以导入增量数据,使用index bootstrap功能去重。
注意:如认为过程耗时,可以在在导入快照数据的同时增加资源以流式写入,减少资源或开启速率限制写入增量数据。
配置
| Option Name | Required | Default | Remarks |
|---|---|---|---|
index.bootstrap.enabled |
true |
false |
When index bootstrap is enabled, the remain records in Hudi table will be loaded into the Flink state at one time |
index.partition.regex |
false |
* |
Optimize option. Setting regular expressions to filter partitions. By default, all partitions are loaded into flink state |
使用步骤
1) CREATE TABLE创建正确table.type类型的表。
2) 设置index.bootstrap.enabled = true开启索引引导功能。
3) 根据检查点调度时间,在flink-conf.yaml中设置检查点失败上限execution.checkpointing.tolerable-failed-checkpoints = n
4) 第一个检查点成功创建时,索引引导配置成功。
5) 索引引导完成后,用户可以退出并保存检查点(或者直接使用外部检查点)。
6) 重启作业,关闭索引引导。
注意
- 索引引导阻塞时,检查点不能成功完成。
- 索引引导由输入数据出发,用户需要保证每个分区中都有数据。
- 索引引导并行执行,可以通过
`finish loading the index under partition和Load record form file观察。 - 首个检查点创建成功即成功,不需要在检查点恢复时重新加载索引。
(4) 变化日志模式
Hudi可以保存所有的中间变化消息,然flink状态计算达到近实时数仓ETL管道(增量计算)的目的。Hudi MOR表以行的形式保存消息,支持保存所有变化日志(在数据格式级别整合)。所有的变化日志记录可以使用flink流式读取器消费。
配置
| Option Name | Required | Default | Remarks |
|---|---|---|---|
changelog.enabled |
false |
false |
It is turned off by default, to have the upsert semantics, only the merged messages are ensured to be kept, intermediate changes may be merged. Setting to true to support consumption of all changes |
注意
- 批量(快照)读取依旧会合并中间变化,不论格式是否保存了中间变化日志消息。
- 当变化日志模式开启时,异步压缩任务会合并变化日志记录到一条记录。如果流式数据源没有及时消费,将只能读取压缩后的记录。可以通过设置压缩选项增加缓冲时间,如compaction.delta_commits和compaction.delta_seconds
(5) 追加模式
INSERT操作,对于COW表默认不会合并小文件,但MOR表会。
COW可开启 write.insert.cluster配置合并小文件。
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.insert.cluster |
false |
false |
Whether to merge small files while ingesting, for COW table, open the option to enable the small file merging strategy(no deduplication for keys but the throughput will be affected) |
(6) 速率限制
| Option Name | Required | Default | Remarks |
|---|---|---|---|
write.rate.limit |
false |
0 |
Default disable the rate limit |