适用于版本0.10.1
1 总览
hudi通过连续映射hoodie key(record key + partition key)和文件id提供高效的更新插入。映射关系从首歌版本的数据写入文件后就不会变化。因此,映射的文件组包含了所有版本的记录。
对于COW表,索引通过避免全部数据集关联,提供了更加快速的更新和删除操作。对于MOR表,索引限制了base文件需要合并的数据量。特别地,base文件只需要合并更新的记录。作为对比,没有索引的组件(如Apache Hive ACID)需要合并所有的base文件。
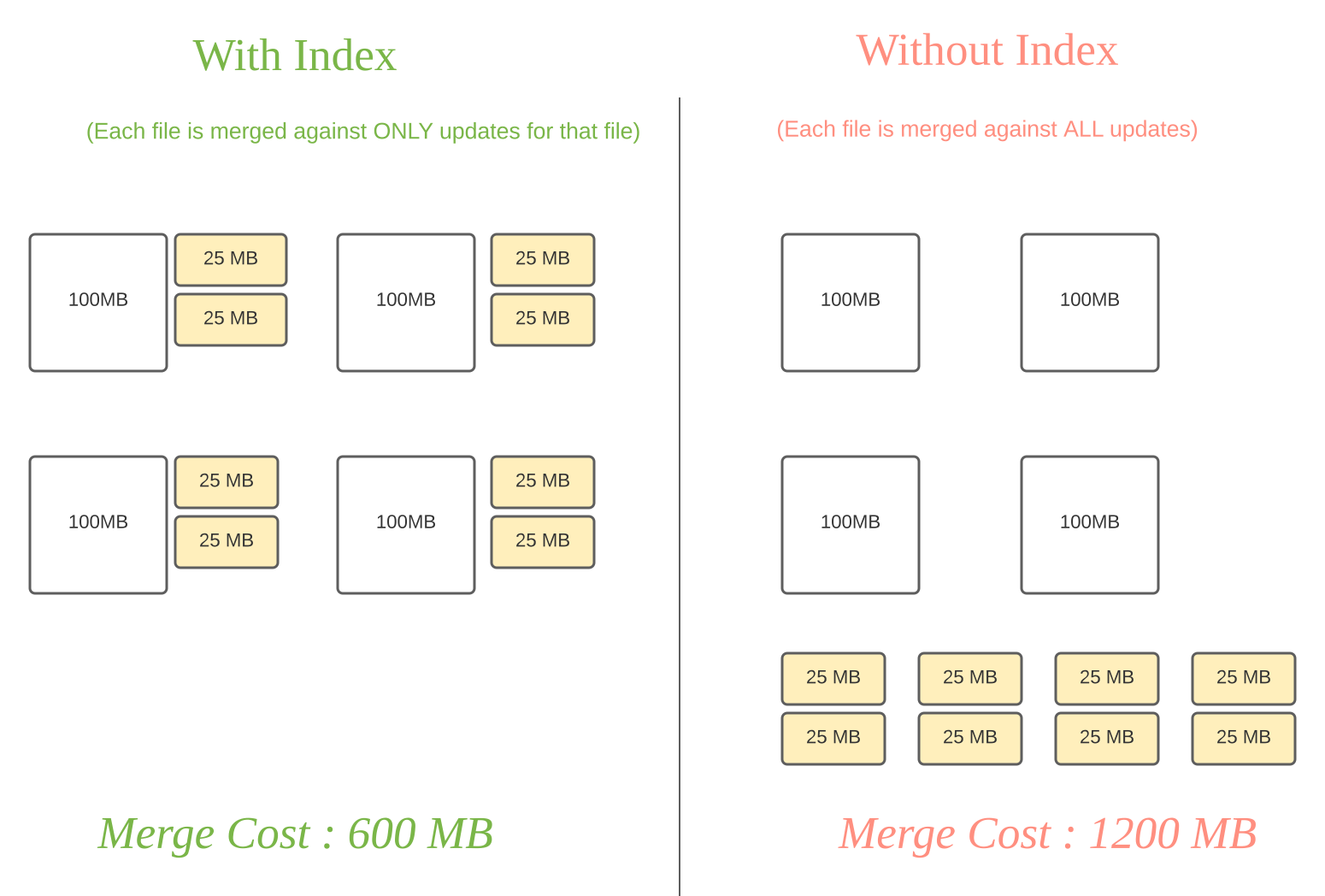
图中白色块表示base文件,黄色块表示数据更新
问题:有无索引时合并成本是600/1200MB, 为什么不是400/800MB?
有索引:(100 + 252) 4
无索引:(100 + 258) 4
2 索引类型
- 布隆索引:对记录键使用布隆过滤器。可选使用记录键范围对候选文件剪枝。
- 简单索引:通过将更新或删除的键与表中提取的键lean join。
- HBase索引:在外部HBase表中映射索引。
- 自定义索引:扩展索引API实现自定义索引。
hoodie.index.type选择索引类型
hoodie.index.class指定自定义索引实现类,Spark场景需要继承SparkHoodieIndex
全局索引与非全局索引:
布隆和简单索引都可配置全局属性,如hoodie.index.type=GLOBAL_BLOOM和hoodie.index.type=GLOBAL_SIMPLE
HBase索引默认全局。
- 全局索引:保证所有分区键值唯一。但是更新或删除代价复杂度O(table size),适用于小表
- 非全局索引:默认方式,保证在分区内键值唯一。更新或删除时需要写入者保证一致的分区路径。复杂度为O(update/delete records), 索引性能更好,适用于大表。
3 索引策略
(1) 事实表迟到更新
由于数据更正等原因可能导致历史数据被更新。
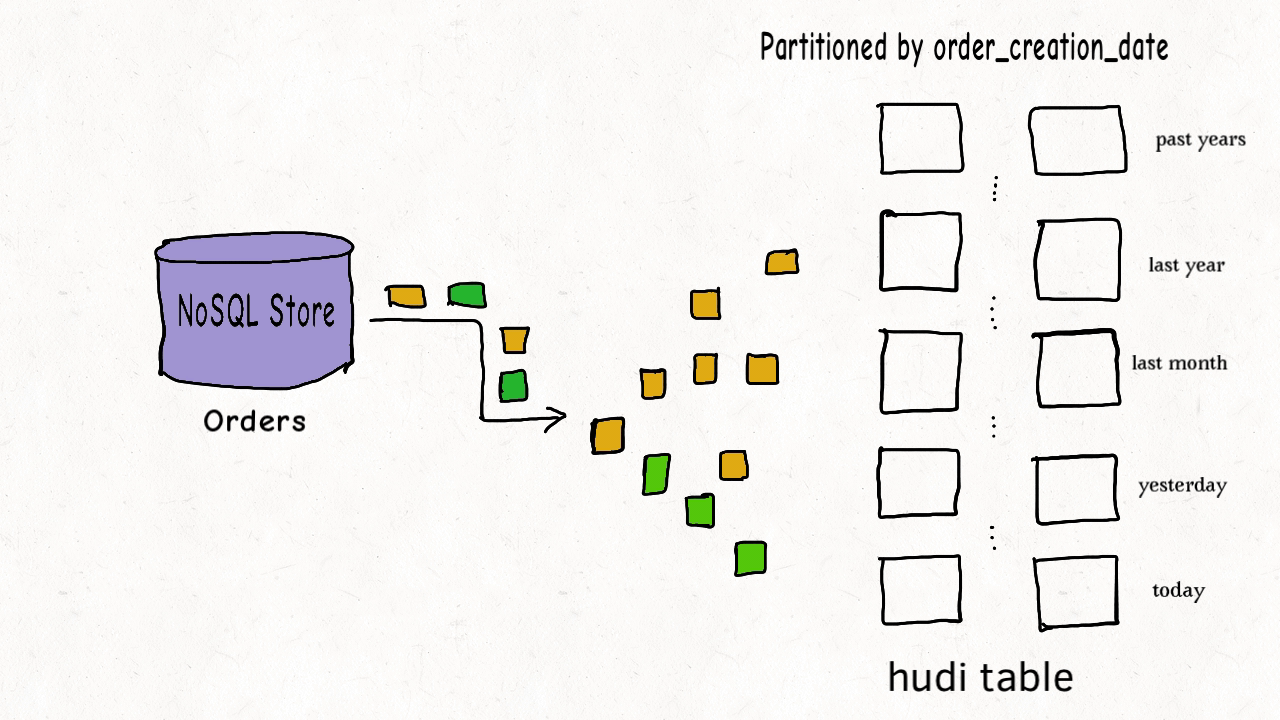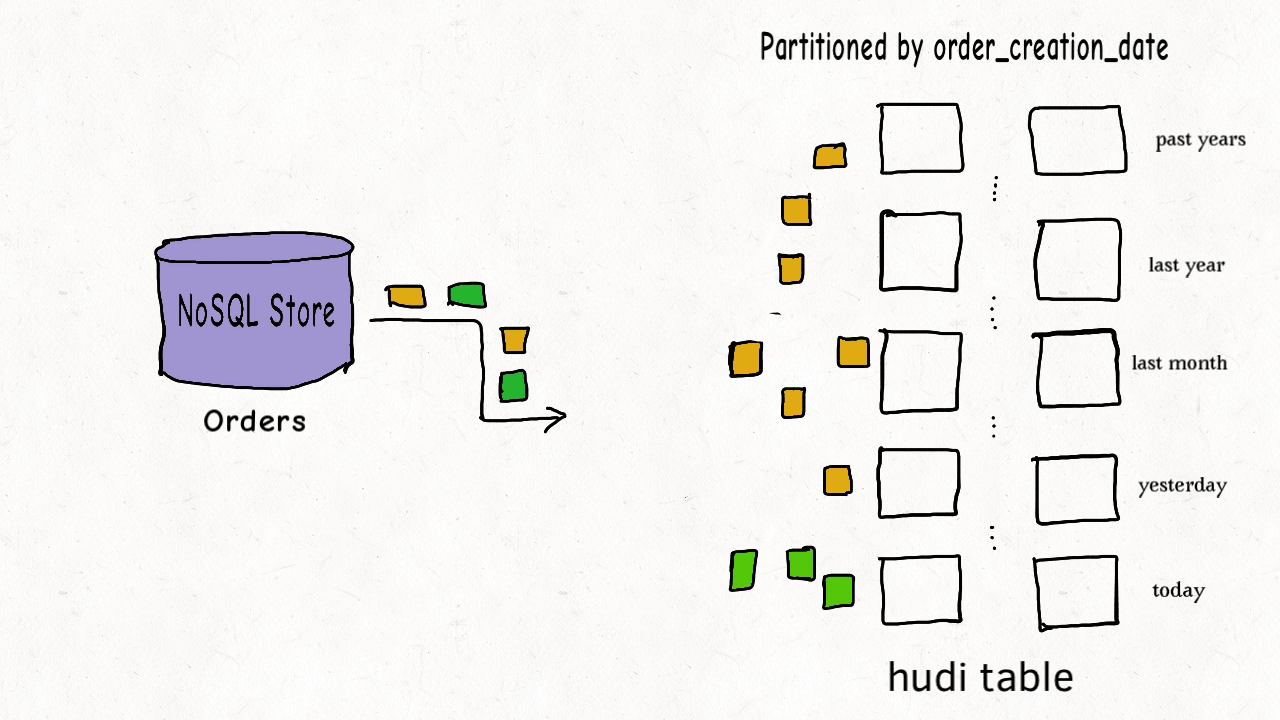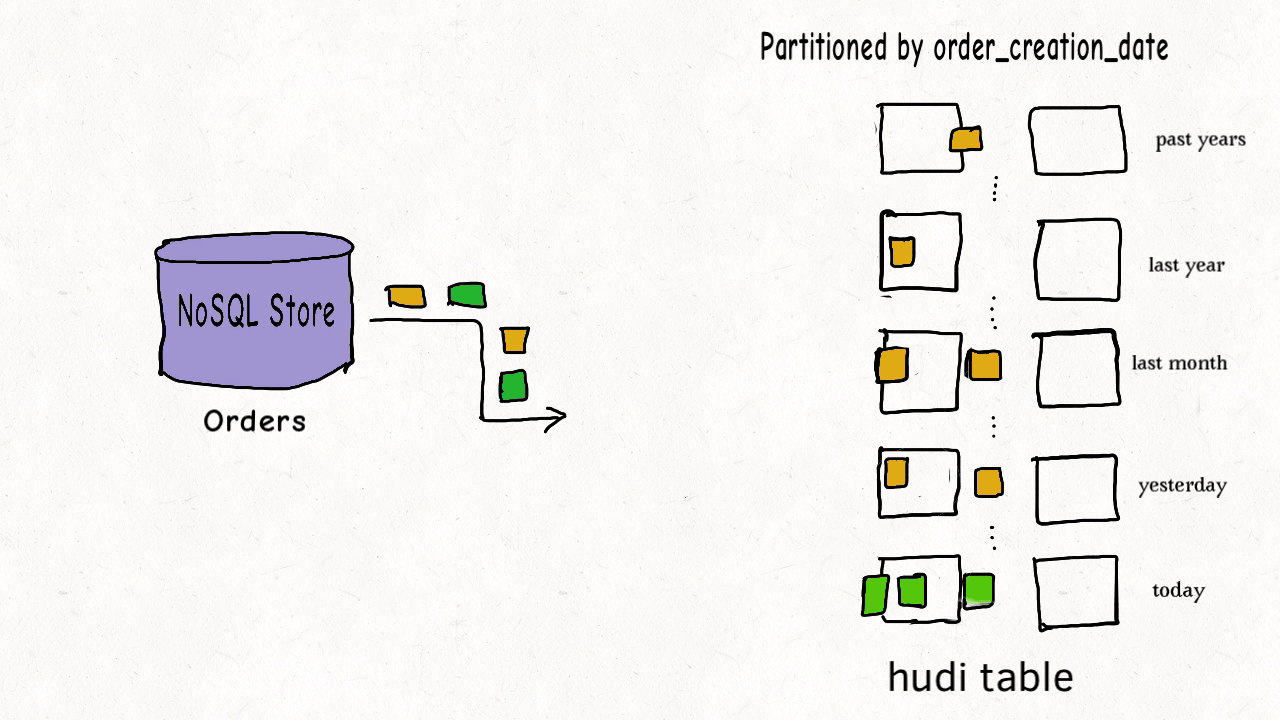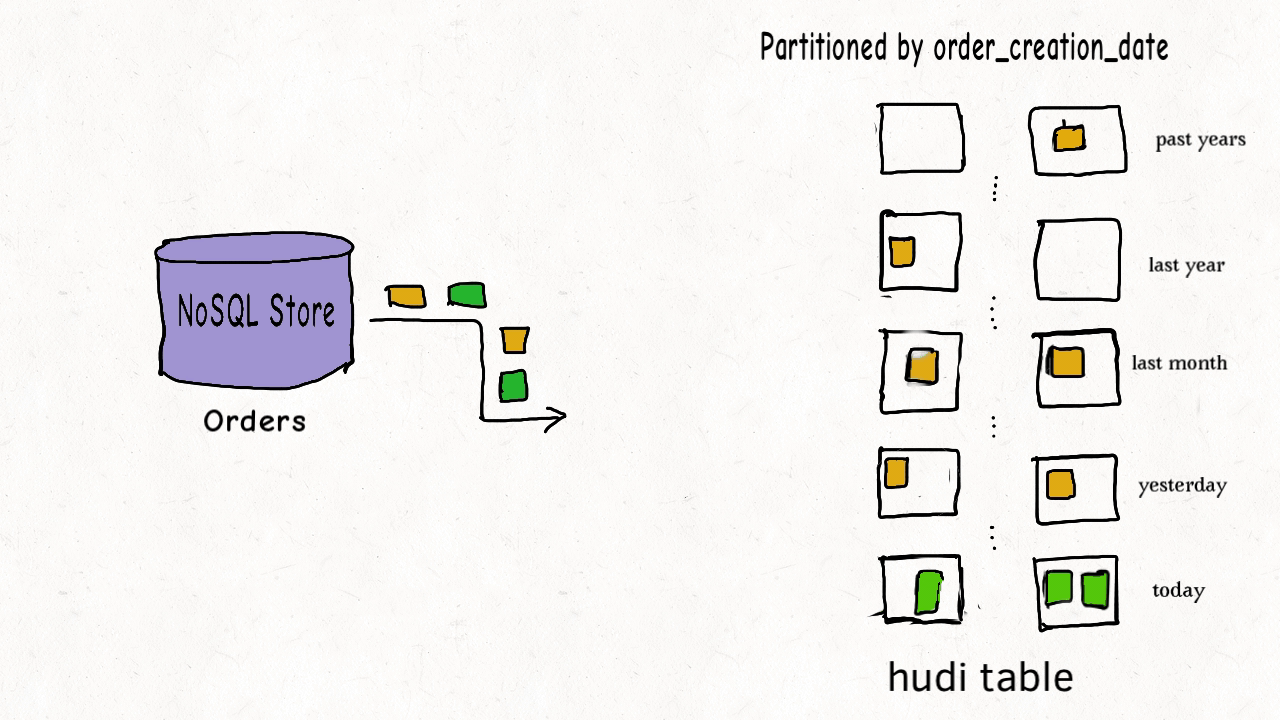
这种场景适用于布隆索引,可在索引时过滤数据文件。并且hudi内部维护有区间树,可根据键值区间过滤文件。
hudi使用缓存和自定义分区器避免数据倾斜。
可以使用动态布隆过滤器体调整大小,降低误报率。hoodie.bloom.index.filter.type=DYNAMIC_V0
(2) 事件表去重
事件流随处可见。通常是事实表的10-100倍。非常看重事件的时间属性,如抵达时间和处理时间。插入和更新只在最近的分区中操作,通常需要在存储前去重。
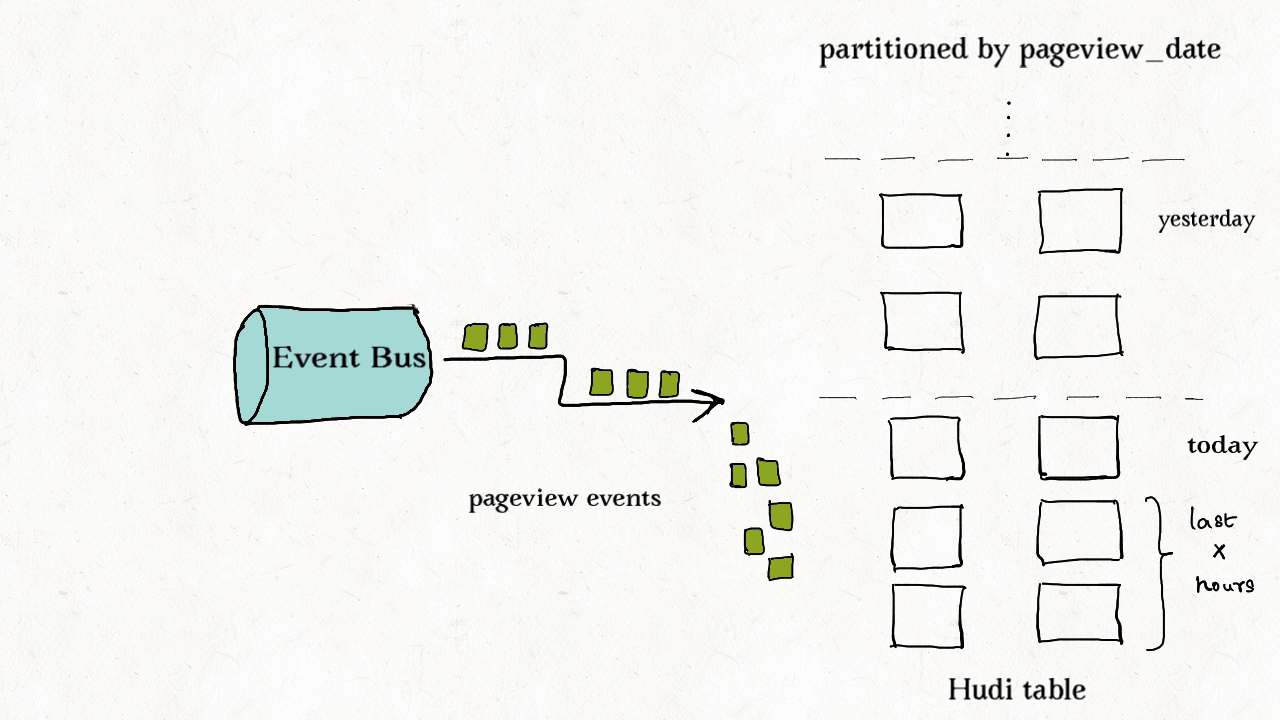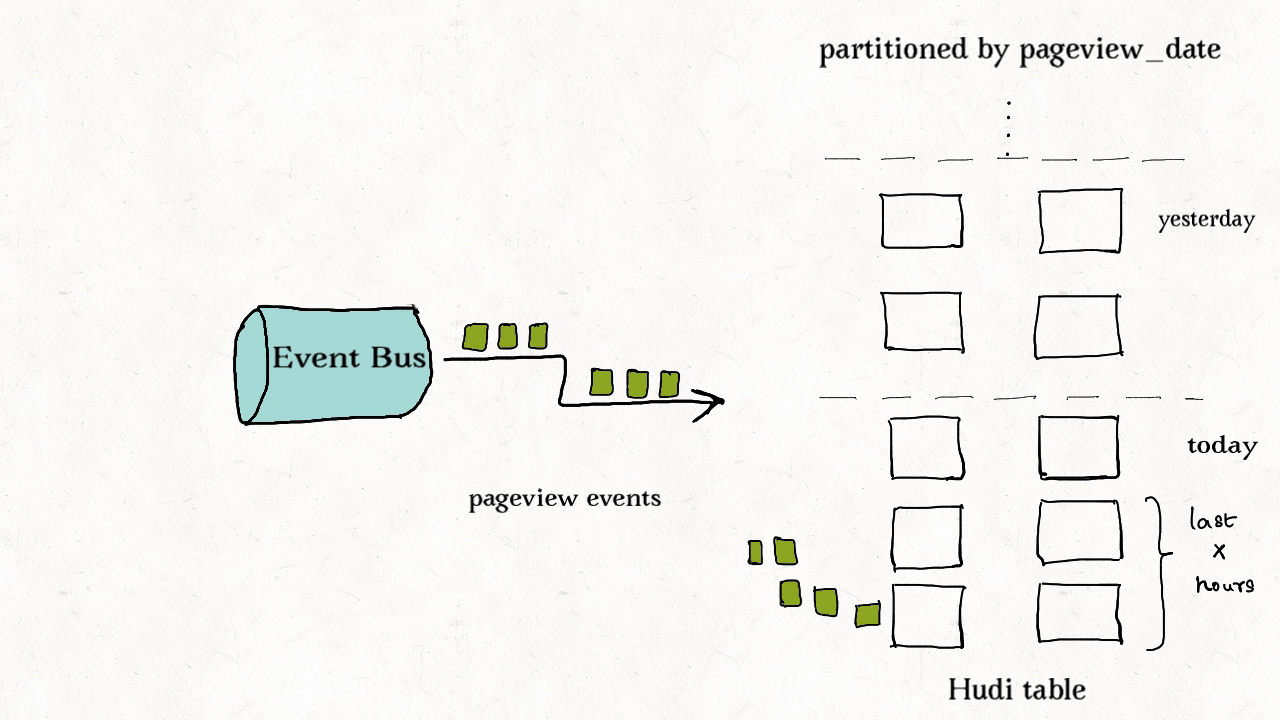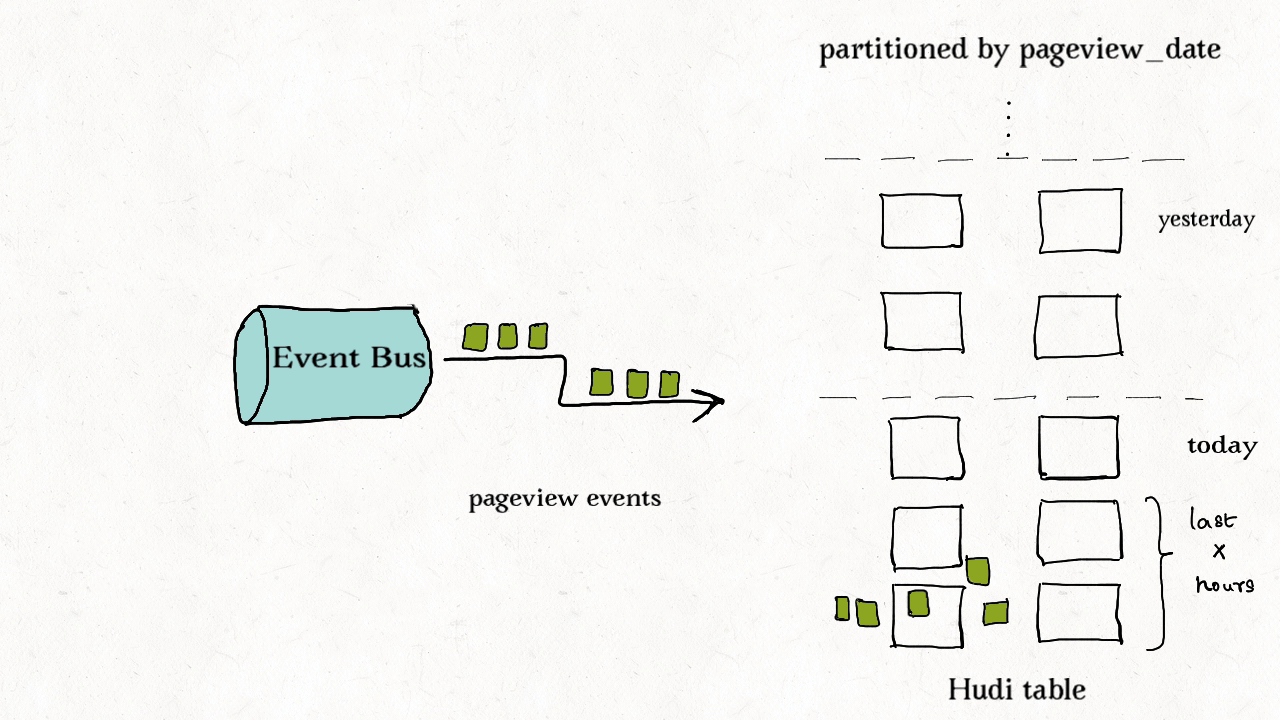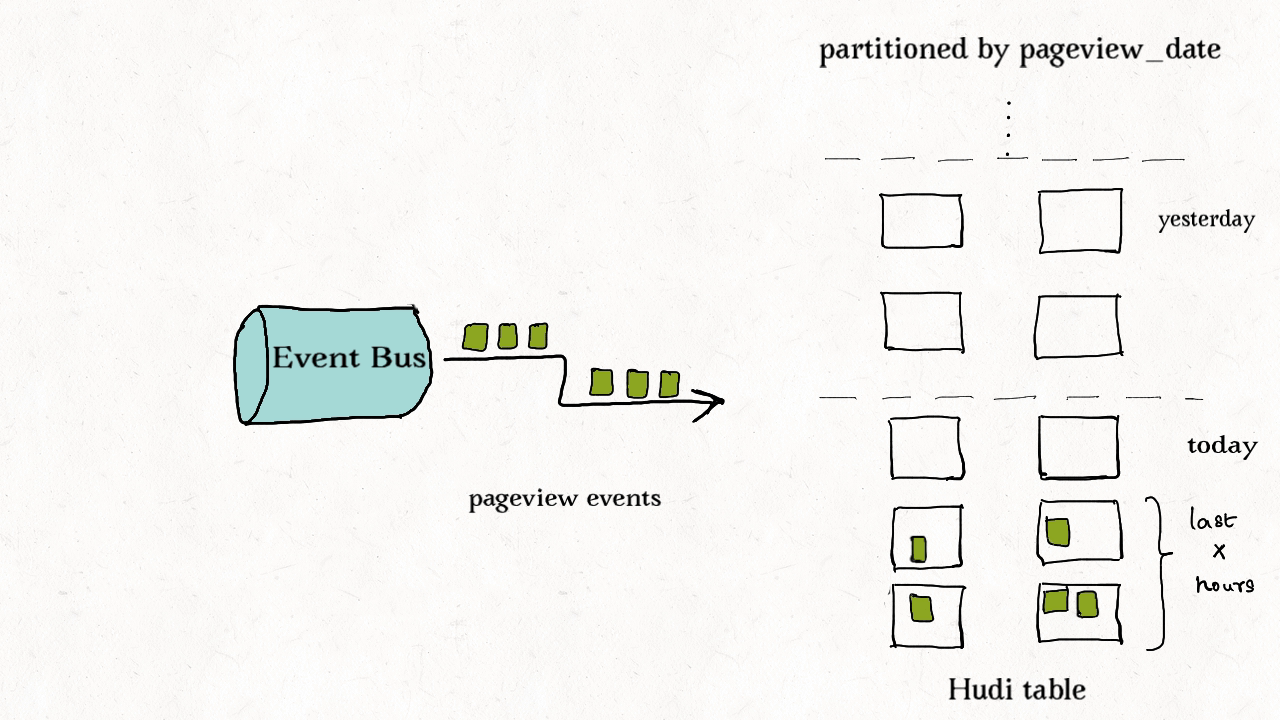
尽管可以使用HBase索引,但是索引成本随事件量线性增加。
这种场景适用于布隆索引。
同时可以使用事件时间+事件id的索引形式保证键值单调递增。
(3) 维度表随机更新或删除
维度表通常是非分区的。其具有高保真的特点,但是更新虽小,但是影响面很大。
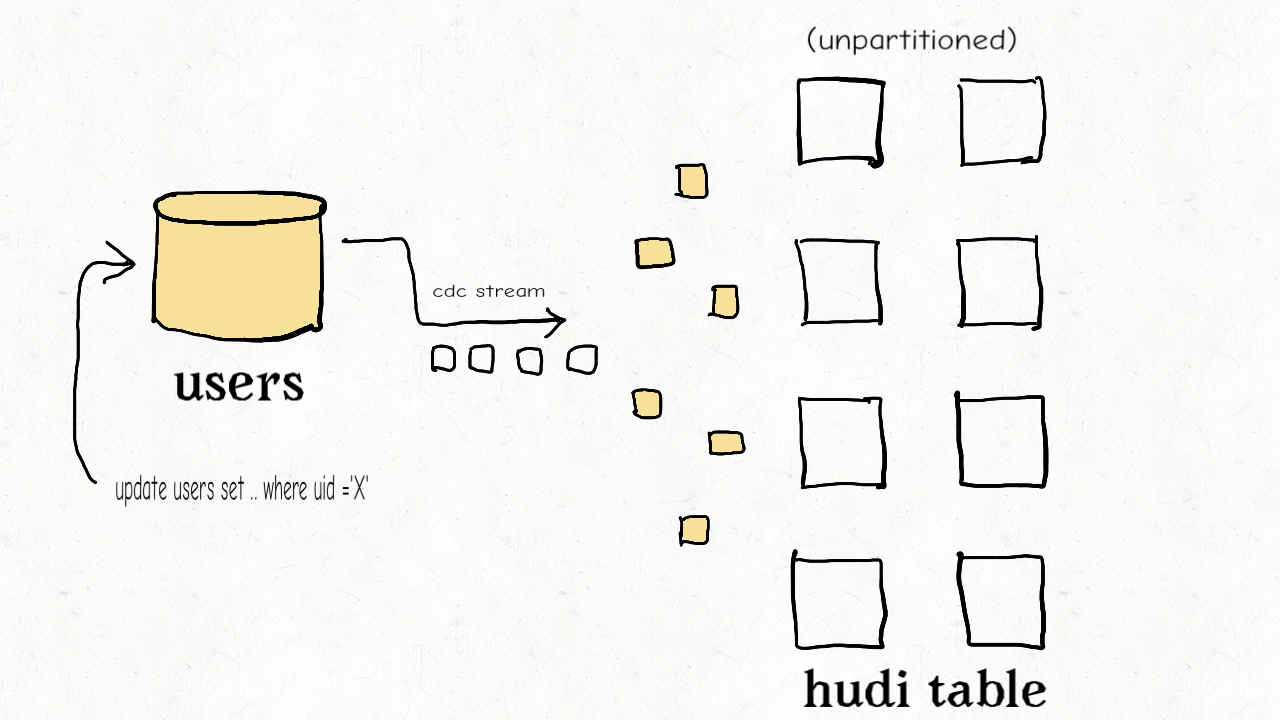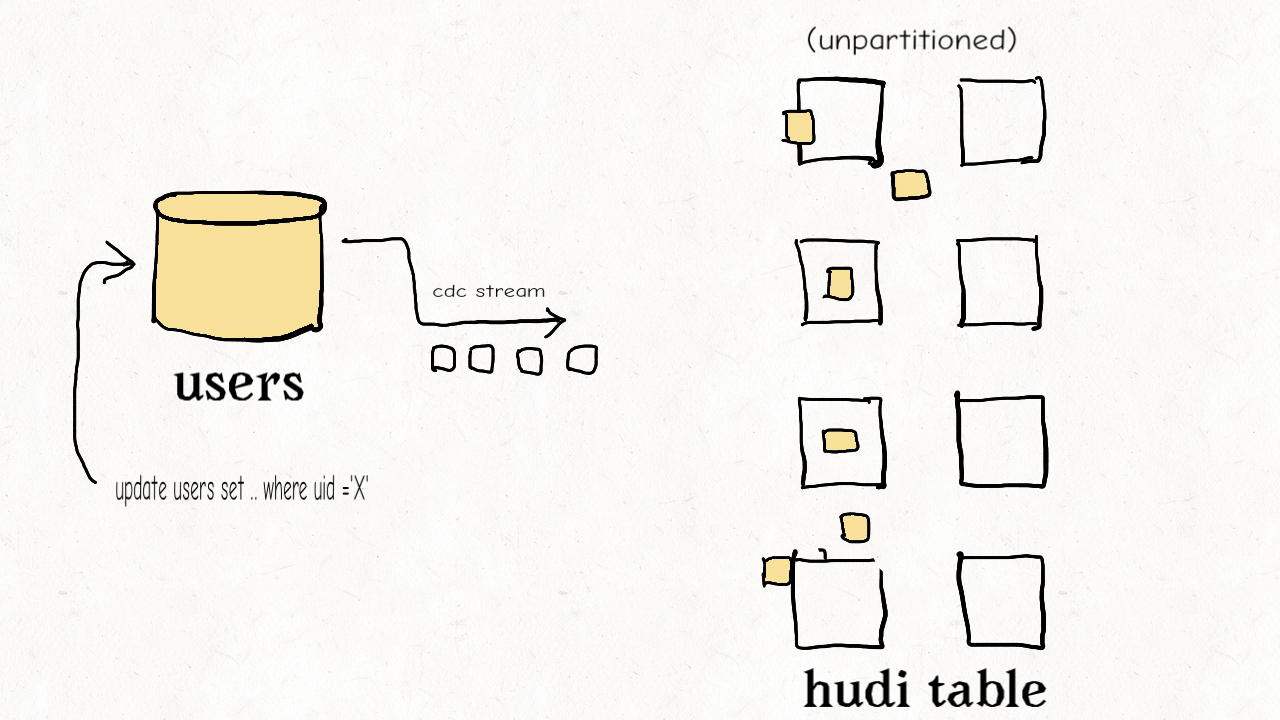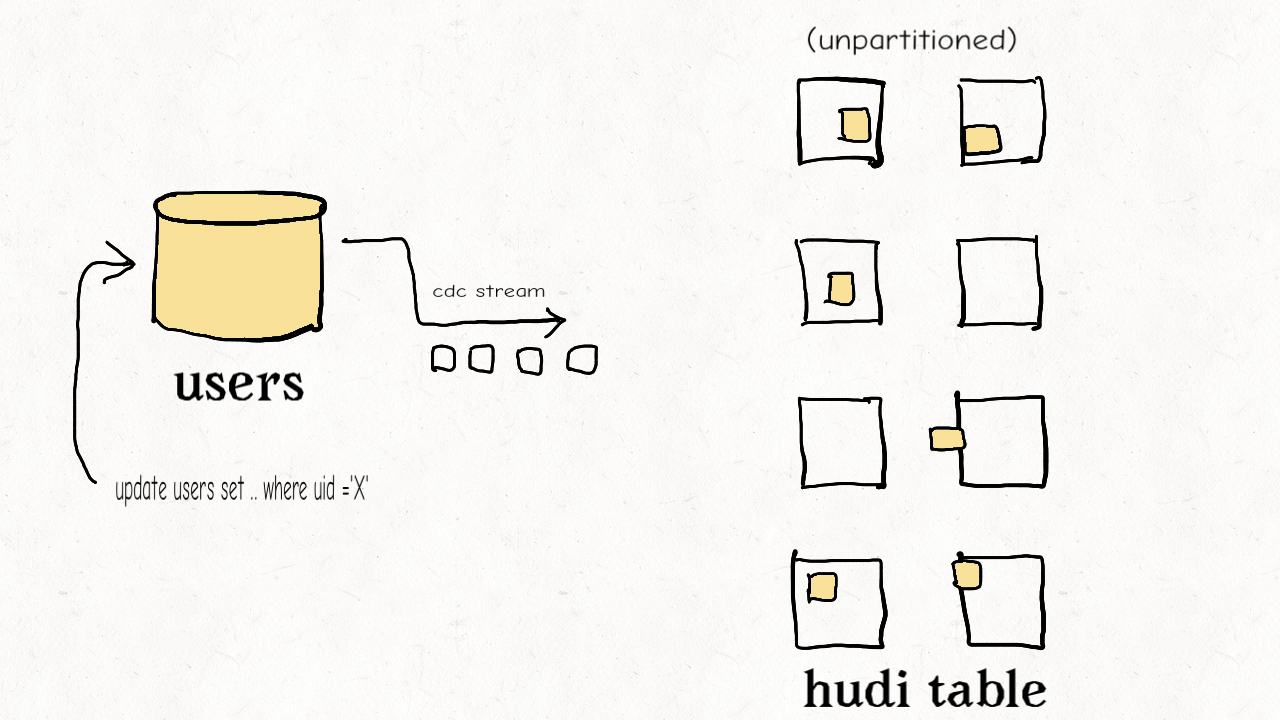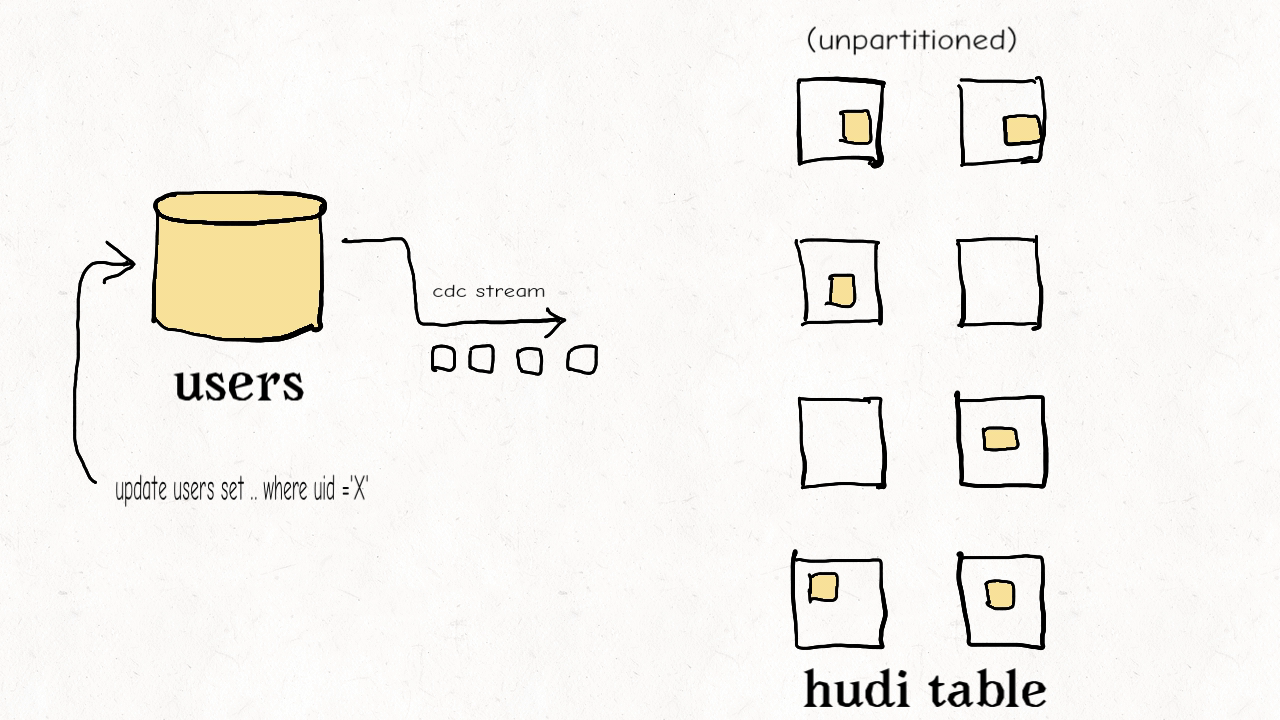
此时,布隆索引因为不能通过键值范围过滤,效果不佳。
可以使用简单索引或HBase索引处理随机更新的场景。
当使用全局索引,并且可能分区路径可能变化时,需要设置hoodie.bloom.index.update.partition.path=true或hoodie.simple.index.update.partition.path=true。