适用于版本0.10.1
1 概览
表类型定义了索引方式和数据在分布式文件系统中的布局,以及相关的功能和时间线活动。如写数据方式。
查询类型定义了数据暴露给查询的方式。如读数据方式
| Table Type | Supported Query types |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
2 表类型
- Copy On Write : 使用单一列文件格式,如parquet。在写入时更新版本并同步合并文件。
- Merge On Read : 使列 + 行文件格式存储,如parquet + avro。更新时写入增量文件,后期同步或异步生成新版本列文件。
优势对比:
cow查询延迟低,存储空间小。mor数据延迟低、IO成本低、写入放大小。
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data Latency | Higher | Lower |
| Query Latency | Lower | Higher |
| Update cost (I/O) | Higher (rewrite entire parquet) | Lower (append to delta log) |
| Parquet File Size | Smaller (high update(I/0) cost) | Larger (low update cost) |
| Write Amplification | Higher | Lower (depending on compaction strategy) |
Write Amplification: 写入放大,写入占用的空间比实际数据量大。因为闪存需要先擦除,再写入。
3 查询类型
- Snapshot Queries : 可以查询最新提交或压缩的数据。
- Incremental Queries : 可以查询从某个提交或压缩开始的数据。
- Read Optimized Queries : 可以查询最新提交或压缩的数据。只暴露base/columnar文件最新的文件分片。保证和非hudi表相同的列查询性能。
优势对比:
快照查询数据延迟低,读优化查询延迟低。
| Trade-off | Snapshot | Read Optimized |
|---|---|---|
| Data Latency | Lower | Higher |
| Query Latency | Higher (merge base / columnar file + row based delta / log files) | Lower (raw base / columnar file performance) |
4 COW表
适用查询为主场景,因为读取放大为0,而写入放大很大。
文件分片只包含base/columnar文件,并且每次提交产生新版本base文件。也就是在每次提交时隐式压缩。
数据写入时,更新操作产生新的数据分片,而插入操作为新的文件组写入第一个数据分片。
查询时过滤书所有最新的文件分片,这样可以避免因为写失败和部分写入导致的查询问题。
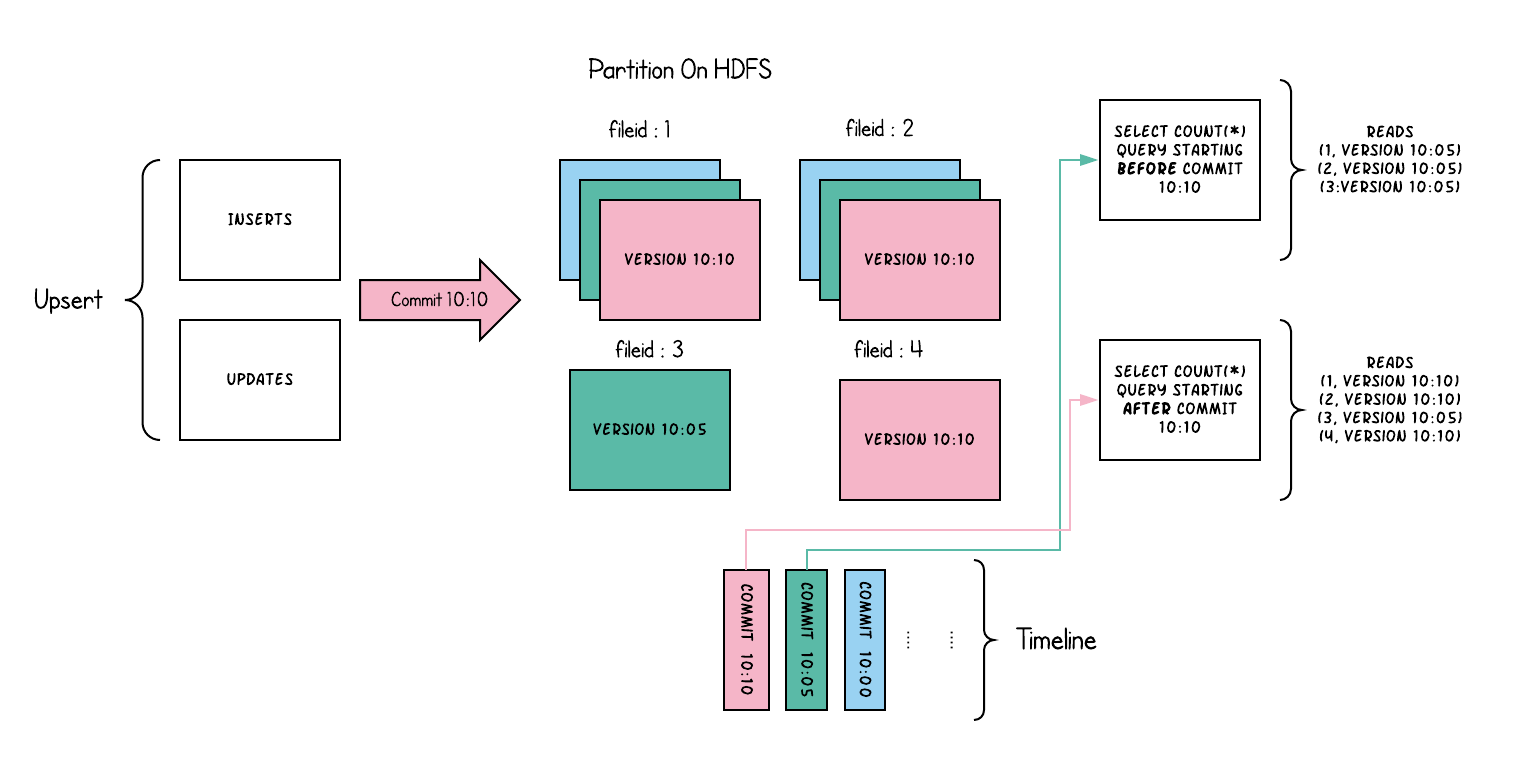
COW表目的:
- 在文件级别上支持原子数据更新,而不是重写整个分区或表
- 增量消费变化数据,而不是浪费地扫描
- 控制文件大小,已避免小文件导致的查询性能降级
5 MOR表
从某种意义上讲,MOR表是COW表的超集,其通过只暴露base/columnar文件的最新文件分片以支持读优化查询。
此外,将更新插入些图到基于行的增量日志中。查询时,通过应用增量日志以支持快照查询。因此可以平衡读取放大和写入放大。
在压缩时,为了避免较大增量日志引发的长时间合并,增量日志将被谨慎选取以保持运行时查询性能。
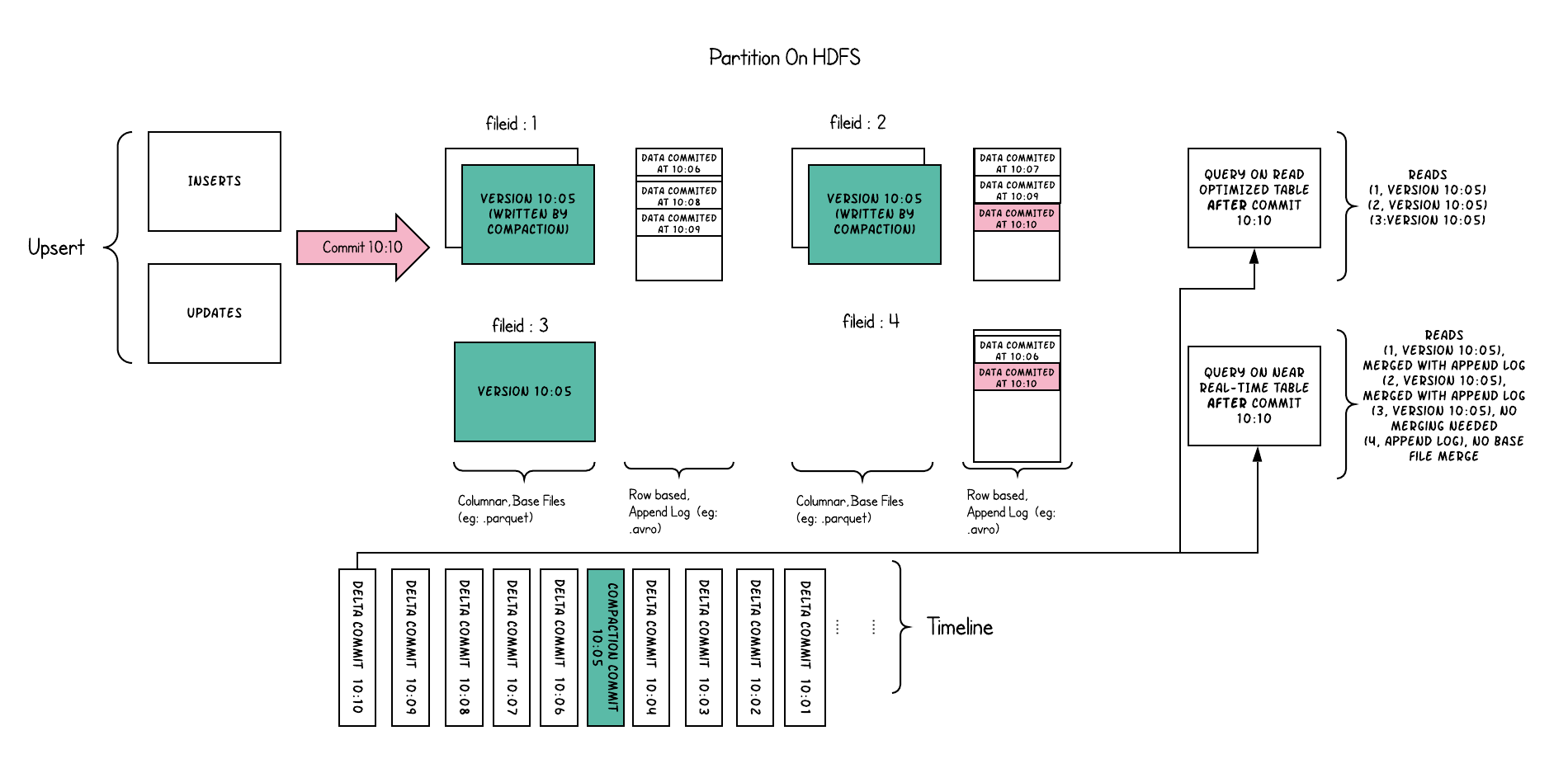
- 每分钟提交一次,数据延迟更低。
- 在每个文件id组中,有一个增量日志记录变化。而base/columnar文件保持现有的版本。如果只查询base文件,那么等同于查COW表。
- 周期性合并增量文件和base文件。
- 两种方式查询:读优化和快照查询,取决于倾向查询性能或数据实时性。
- 提交的数据何时可用于读优化查询是不确定的。但是可以保证快照查询读取的都是最新的数据。
- 通过应用压缩策略,读优化查询可以查询一段连续时间内的数据。
MOR表的设计意图是直接在DFS上进行准实时处理,而不是将数据拷贝到其他系统。由于避免了数据同步合并,同时也降低了写入放大。