1 Spark Core
(1) ExecutorPlugin
org.apache.spark.ExecutorPlugin替换为org.apache.spark.api.plugin.SparkPlugin。
⚠️注意区分org.apache.spark.api.plugin.ExecutorPlugin
用于动态加载插件到Spark中。分为Driver自动加载的单例DriverPlugin和Executor控制加载的ExecutorPlugin。
详见Monitor
(2) TaskContext
isRunninglocally()用于判断任务是否在驱动节点执行,已移除
(3) ShuffleWriterMetrics
替换shuffleBytesWritten、shuffleWriteTime和shuffleRecordsWritten为bytesWritten、writeTime和recordsWritten
因为前者是为了兼容以前的接口。
(4) AccumulableInfo
移除apply方法,因为不允许程序创建AccumulableInfo
(5) Accumulator
移除V1接口
(6) Event Log
采用UTF-8编码,而不是Driver JVM进程的默认编码。
历史服务因为需要兼容,会执行一次转码。
(7) Shuffle Block Protocol
版本3.0使用了一种新的获取Shuffle Block的协议。
推荐版本3.0应用使用版本3.0的External Shuffle Service,否则使用旧版本需要设置spark.shuffle.useOldFetchProtocol,以防报错IllegalArgumentException: Unexpected message type: \
(8) SPARK_WORKER_INSTANCE
在Standalone模式中已标记弃用。
推荐在一个节点运行一个Worker,一个Worker中运行多个Executor。而不是多个Worker中运行一个Executor。
2 Spark SQL
(1) Dataset/Dataframe API
1) unoinAll
不再标记弃用,成为union的别名。
2) Dataset.groupByKey
返回的结果是一个带有key的聚合dataset, 但是key的名称被错误命名为value。如ds.groupByKey(…).count()的结果是(value, count)。
版本3.0将键名修正为key。
使用旧版本命名需要设置spark.sql.legacy.dataset.nameNonStructGroupingKeyAsValue。
3) Column Metadata
在Column.name和Column.as中传播。
之前版本,仅在调用API时为新列设置名为explicitMetadata的NamedExpression元数据。之后即使NamedExpression改变了元数据也不变。
使用旧版本可以调用as(alias: String, metadata: Metadata)接口。
(2) DDL
1) Type Coercion
版本3.0在插入不匹配的类型时,类型转换遵循ANSI标准。
如string转int和double转boolean不再被允许。数值溢出将抛出异常。
之前的版本允许合法的类型的转换,并且按照Java/Scala截取溢出的数值。
以上行为由spark.sql.storeAssignmentPolicy控制,默认ANSI。使用旧版本可设置为Legacy。
2) ADD JAR
指令返回空的结果集,而不是包含数值0的结果集
3) SET
使用SET设置SparkConf时报错,因为SET命令不会更新SparkConf配置。
之前版本直接忽略。
使用旧版本可以关闭spark.sql.legacy.setCommandRejectsSparkCoreConfs
4) Refresh Cached Table
取消缓存前,先存储缓存名称和存储等级;再取消缓存,最后惰性缓存。
之前版本不会存储名称和等级,容易导致前后不一致。
5) 保留字
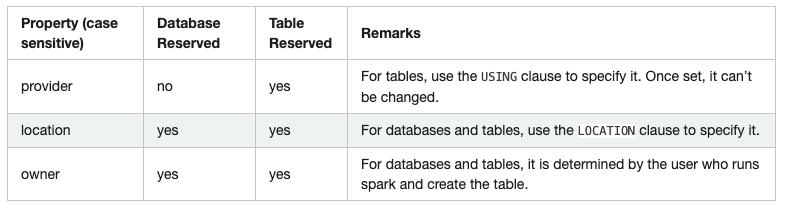
保留字需要在正确的位置使用,否则失败。如CREATE DATABASE test COMMENT ‘any comment’ LOCATION ‘some path’。
而CREATE DATABASE … WITH DBPROPERTIES和ALTER TABLE … SET TBLPROPERTIES中设置将会失败。
可以设置spark.sql.legacy.notReserveProperties忽略ParseException。
直接设置属性将不会生效,如SET DBPROPERTIES(‘location’=’/tmp’)。
之前版本中设置属性不会生效,但会产生无用的属性,如’a’=’b’
6) ADD FILE
支持添加目录
之前版本只能逐个文件添加
使用旧版本可以设置spark.sql.legacy.addSingleFileInAddFile
7) SHOW TBLPROPERTIES
表不存在抛出AnalysisException异常,而不是NoSuchTableException。
8) SHOW CREATE TABLE
返回Spark DDL,即使是Hive SerDe Table。
生成Hive DDL需要使用SHOW CREATE TABLE AS SERDE。
9) CHAR
不允许在非Hive SerDe表中使用CHAR列,建议使用STRING类型。在CREATE/ALTER TABLE 中使用将会失败。
之前版本CHAR类型当作STRING类型处理,并简单忽略长度参数。
(3) UDF和内建函数
1) date_add和date_sub
第二个参数只支持int、smallint和tinyint类型,不再支持小数和字符串。如date_add(cast(‘1964-05-23’ as date), ‘12.34’)将会抛出异常。
2) percentile_approx (approx_percentile)
accuracy参数只支持[1, 2147483647]范围内的整型值,不再支持小数和字符串。
3) hash expression
应用到MapType时抛出异常AnalysisException
使用旧版本设置spark.sql.legacy.allowHashOnMapType
4) array/map function
无参调用时返回元素类型为NullType的空集合,而不是元素类型为StringType的空集合。
使用旧版本设置spark.sql.legacy.createEmptyCollectionUsingStringType
5) from_json
支持两种模式:PERMISSIVE(默认)和FAILFAST。
之前版本以以上两种模式不同,尤其是对于错误格式的JSON。如{“a” 1}将INT转换为null类型,而新版本转换为Row(null)。
6) 创建map类型的map键值
不再支持使用内部函数创建map类型的mapl键值,如CreateMap, MapFromArrays等。
可以但不建议读取map类型的map键值。
可以使用map_entries将map转换为array<struct<key, value»中间类型过渡。
7) 使用重复key创建map
不再支持使用重复key创建map,否则抛出异常RuntimeException。
之前版本会导致不一致的行为,如map查找返回找到第一个键值,Dataset.collect只保存出现的最后一个键值,MapKeys返回重复的键名等。
使用最后一个出现的键值,可以设置spark.sql.mapKeyDedupPolicy为LAST_WIN。
读取依旧需要注意不一致的行为问题。
8) org.apache.spark.sql.functions.udf(AnyRef, DataType)
默认不再允许。
可以移除返回类型以转换为带类型的udf函数,或者设置spark.sql.legacy.allowUntypedScalaUDF继续使用。
之前版本对于null基本类型的输入,返回null。
由于版本3.0使用Scala 2.12构建,会返回默认值。
9) exists
高阶函数exist遵循three-valued boolean logic。
如果predicate返回null,并且没有得到true,exists将返回null,而不是false。如exists(array(1, null, 3), x -> x % 2 == 0)返回null
使用旧版本可以关闭spark.sql.legacy.followThreeValuedLogicInArrayExists
10) add_months
对当月最后一日,不再设置为另一月最后一日。
如select add_months(DATE’2019-02-28’, 1)返回2019-03-28,而不是2019-03-31
11) current_timestamp
如果系统时钟支持,可以返回毫秒单位时间戳。
之前版本只支持微秒单位。
12) 无参Java UDF
与其他UDF一样在执行器侧执行。
之前版本在驱动侧执行,然后传播到执行器侧。虽然高效,但是某些场景会导致不一致。
13) java.lang.Math中log、log1p、exp、expm1和pow
与java.lang.StrictMath结果保持一致
之前版本可能因为平台不同而不同。
14) cast
转换为double或float类型时,‘Infinity’, ‘+Infinity’, ‘-Infinity’, ‘NaN’, ‘Inf’, ‘+Inf’, ‘-Inf’大小写不敏感,为了与其他数据库系统保持一致
之前版本大小写敏感。
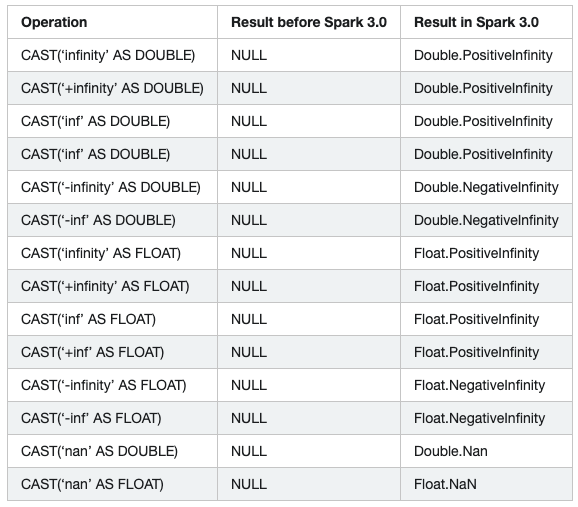
15) interval
时间间隔转字符串是不再带有“interval ”字样。
之前版本形如“interval 1 days 2 hours”。
16) string
字符串转整型、时间和布尔类型时,去除前后的空白符(<= ANSI 32)。
之前版本只在转时间类型时删除末尾的空格(= ANSI 32)。
(4) 查询引擎
1) FROM \ SELECT \
SELECT \
之前版本意外支持FROM <table>或FROM <table> UNION ALL FROM <table>
2) interval from-to
不再支持多个from-to,如SELECT INTERVAL ‘1-1’ YEAR TO MONTH ‘2-2’ YEAR TO MONTH’,否则抛出解析异常。
3) 科学计数
科学计数将被转换为双精度,而不是Decimal.
使用旧版本设置spark.sql.legacy.exponentLiteralAsDecimal.enabled
4) 时间区间字符串
时间区间字符串被转换为带有from和to的边界。如果模式不匹配,将抛出异常ParseException。
如interval ‘2 10:20’ hour不匹配[+|-]h[h]:[m]m模式,将抛出异常。
之前版本不考虑from边界,to边界只用于过滤结果。以上示例将转换为interval 10 hours 20 minutes。
使用旧版本可设置spark.sql.legacy.fromDayTimeString.enabled
5) Decimal?
默认不支持Decimal的负值范围。
如1E10BD将转换为DecimalType(11, 0),而不是DecimalType(2, -9)。
使用旧版本可设置spark.sql.legacy.allowNegativeScaleOfDecimal
6) +
一元算术操作符只允许字符串、数值和区间类型作为输入。
其中与整型字符串搭配,将转换为双精度。如+ ‘1’返回1.0
之前版本没有类型检查和转换。
7) self join
包含不明确列值的Dataset自身关联将失败。
如val df1 = …; val df2 = df1.filter(…);执行操作df1.join(df2, df1(“a”) > df2(“a”))将返回空集合。其中df1(“a”)等价于df2(“a”)
使用旧版本可关闭spark.sql.analyzer.failAmbiguousSelfJoin
8) spark.sql.legacy.ctePrecedencePolicy
用于处理嵌套WITH中的命名冲突。
EXCEPTION抛出异常AnalysisException。
CORRECTED取前面最近的定义。
LEGACY取最外面的定义。
如WITH t AS (SELECT 1), t2 AS (WITH t AS (SELECT 2) SELECT FROM t) SELECT FROM t2在CORRECTED返回2,而LEGACY返回1
9) spark.sql.crossJoin.enabled
成为内部配置,并默认开启。因此隐式cross join不会抛出异常。
10) 浮点0.0
浮点正负0.0在用做聚合分组键、窗口分区键和关联键时等价。
如Seq(-0.0, 0.0).toDF(“d”).groupBy(“d”).count()返回[(0.0, 2)]
11) timezone id
非法id将抛出异常java.time.DateTimeException,而不是设置为GMT时区。
12) 格里高利历
使用遵循ISO chronology的Java 8 API中的java.time,而不是Julian + Gregorian。主要影响1582-10-15之前的时间。
时间、字符串解析和格式化
严格按照Datetime Patterns for Formatting and Parsing解析
如2015-07-22 10:00:00不再部分匹配yyyy-MM-dd,31/01/2015 00:00不再匹配带有12小时制hh的dd/MM/yyyy hh:mm。
之前版本使用java.text.SimpleDateFormat。
使用旧版本可设置spark.sql.legacy.timeParserPolicy为LEGACY
第几天
使用java.time API 计算
JDBC options lowerBound和upperBound
转换为时间戳或日期类型,同字符串转换,使用格里高利历和spark.sql.session.timeZone配置的时区。
之前版本使用儒略历和系统时区。
格式化时间戳和日期字面量
string to time
使用类型转换操作,时区采用spark.sql.session.timeZone。如TIMESTAMP ‘2019-12-23 12:59:30’等价于CAST(‘2019-12-23 12:59:30’ AS TIMESTAMP)
之前版本使用JVM系统时间。
13) TIMESTAMP to string
使用spark.sql.session.timeZone配置的时区,而不是JVM默认时区。
14) string to DATE/TIMESTAMP
在二进制上进行类型转换?
使用旧版本可开启spark.sql.legacy.typeCoercion.datetimeToString.enabled
15) 特殊时间值
DATE
如查询 SELECT date 'tomorrow' - date 'yesterday';返回2
1 | epoch [zoneId] - 1970-01-01 |
TIMESTAMP
1 | epoch [zoneId] - 1970-01-01 00:00:00+00 (Unix system time zero) |
16) EXTRACT
提取DATE/TIMESTAMP的秒信息是,返回DecimalType(8, 6)类型,而不是IntegerType。
如extract(second from to_timestamp(‘2019-09-20 10:10:10.1’))返回10.100000,而不是10
17) datetime F
代表当月从1日为第一周的第一天,当前周的第几天。如2020-07-30返回2(第5周的第2天)
之前版本返回当前所在的自然周数,如2020-07-30返回5。注意此时第一周是07.01-07.04。
(5) 数据源
1) Hive SerDe
使用原生数据源(如parquet/orc)读取Hive SerDe表时不再推断Schema并更新metastore。
预期不会对用户产生影响,使用旧版本可设置spark.sql.hive.caseSensitiveInferenceMode为INFER_AND_SAVE。
2) partition column
分区字段不能转换为用户Schema时,抛出异常,而不是转换为null。
使用旧版本可关闭spark.sql.sources.validatePartitionColumns
3) 文件递归
在文件递归时,文件或子目录消失将导致失败,而不是忽略。
使用旧版本可开启spark.sql.files.ignoreMissingFiles
Note that this change of behavior only applies during initial table file listing (or during REFRESH TABLE), not during query execution: the net change is that spark.sql.files.ignoreMissingFiles is now obeyed during table file listing / query planning, not only? at query execution time.
4) 空字符串
解析JSON数据源时,不允许空字符串,除了StringType和BinaryType。
之前版本会将IntegerType等转换为null。
使用旧版本可开启spark.sql.legacy.json.allowEmptyString.enabled
5) 错误JSON格式
在使用JSON数据源和JSON函数时(PERMISSIVE mode, StructType),允许部分解析错误JSON格式记录中的字段,而不是返回一个所有字段都为null的数据。
6) 推断JSON TIMESTAMP
如果匹配SON option timestampFormat,JSON数据源和schema_of_json函数将自动推断时间戳字符串。
可通过设置JSON option inferTimestamp为false关闭。
7) CSV
在PERMISSIVE 模式下,允许部分解析错误CSV格式中的字段。
8) Avro Filed
使用用户Schema保存时,按名称匹配,而不是按位置。
9) Avro Nullable
可以将Nullable的Catalyst Schema写出到Non-nullable的Avro Schema。但是一旦出现null值将抛出空指针异常。
(6) 其他
1) cloneSession()
新创建的SparkSession优先继承SparkSession属性,而不是SparkContext。
使用旧版本开启spark.sql.legacy.sessionInitWithConfigDefaults
2) hive.default.fileformat
如果在Spark SQL configuration中没有找到,使用Hadoop configuration of SparkContext中的配置。
3) spark-sql
小数添加后置0

4) hive
内置hive从版本1.2升级到2.3
- 连接特定版本的Hive Metastore需要设置spark.sql.hive.metastore.version和spark.sql.hive.metastore.jars
- 迁移自定义的SerDe,或者编译特定hive版本的Spark
- 在脚本中使用TRANSFORM,需要注意不同的小数表示。Hive 2.3总是填充到18位小数,而Hive1.2总是忽略。