查询优化、索引优化和库表结构优化需要齐头并进。
查询优化的目的:
- 不做无用的操作
- 快速计算
1 数据访问优化
针对慢查询,需要检查:
- 应用程序是否请求了多余的数据
- MySQL是否扫描了多余的数据
(1) 请求过量
1) 查询多余的数据
MySQL总是返回所有的结果集再计算,需要使用LIMIT限制查询的数据规模
2) 多表关联返回全部列
多表关联全取将返回所有表的列,需要限制返回的列
3) 取出所有列
全取无法使用覆盖索引
4) 重复查询
缓存有助于提升性能
(2) 扫描过量
衡量查询开销的指标可以在慢查询日志中查看:
- 响应时间
- 扫描行数
- 返回行数
1) 响应时间
响应时间包括:
- 服务时间:查询实际耗费
- 排队时间:等待资源时间
为了衡量响应时间是否合理,可以使用快速上限估计估算。综合考虑索引、执行计划、顺序和随机I/O、每次I/O时间。详见Lahdenmaki T, Leach M. Relational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al[M]. John Wiley & Sons, 2005.
2) 扫描行数和返回行数
理想情况下扫描行数应该等于返回行数。
优化应尽可能减少数量。
3) 扫描行数和访问类型
全表扫描-索引扫描-范围扫描-唯一索引查询-常数引用,速率依次提升,扫描行数依次减少
最简便的提升方法是添加索引。
从好到坏,MySQL处理WHERE条件的方式:
- 索引过滤,存储引擎层完成
- 覆盖扫描返回记录+索引过滤,服务器层完成
- 记录过滤,服务器层完成
扫描行数过多处理方法:
重构查询
覆盖索引
- 改变库表结构,如增加汇总表
2 重构查询
(1) 切分查询
在尽可能小地影响性能和延迟的前提下,将一个复杂、庞大的查询切分为多个简单的查询,可以减少服务器一次性的压力,并且分散到一段时间中。如删除数据。
1 | rows_affected = 0 |
(2) 分解关联查询
使用应用程序缓存查询结构,在应用程序处处理数据关联问题。
优点:
- 缓存效率更高
- 可以重复利用,减少重复查询
- 减少锁竞争
- 应用层关联利于数据库拆分,易于高性能和可扩展。如使用哈希关联替代嵌套关联
- 通过IN()顺序查询替代关联查询,优于随机查询
3 查询执行基础
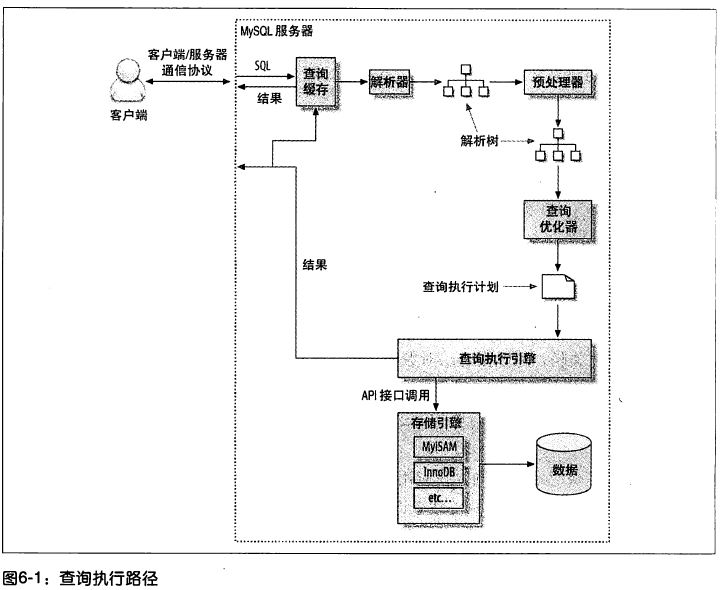
1 客户端发送查询请求给服务器
2 服务器检查查询缓存,返回缓存或进入下一步
3 服务器对SQL解析、预处理,经优化器后生成执行计划
4 服务器调用存储引擎API执行查询
5 服务器返回结果给客户端
(1) 客户端/服务器通信协议
半双工:同一时刻只能单向通信。无法流量控制,一旦传输只能等待完成。
客户端发送一个单独的包给服务器,如果包过大,需要设置max_allowed_packet:如果查询过大,拒绝接收并报错。
服务器返回多个包给客户端,需要控制返回的数据量。
多数连接MySQL的库函数都是获取全部结果集并缓存到内存中。但是在整个查询过程中资源都被锁定,需要注意资源占用量。
查询状态,可以通过SHOW FULL PROCESSLIST命令获取:
- Sleep:等待新请求
- Query:正在查询或返回结果
- Locked:正在等待表锁。存储引擎级别的锁不会出现在线程查询状态中
- Analyzing and statistics:收集统计信息,并生成查询计划
- Copying to tmp table [on disk]:正在执行查询,并将结果复制到临时表中
- Sorting result:排序
- Sending data:状态间数据传输,或生成结果集,或返回结果
(2) 查询缓存
通过大小写敏感的哈希(包含SQL注释的)查找缓存,命中并且具有权限则返回缓存,避免了SQL解析、生成计划和执行等后续操作。
(3) 查询优化处理
1) 语法解析器和预处理器
解析器验证语法规则(如关键字、顺序和引号配对等),并将SQL语句解析为“解析树”。
预处理器验证解析树和权限。如数据是否存在和别名等
2) 查询优化器
优化器应用优化规则将“解析树”转化为执行计划。
MySQL使用基于成本的优化器选择执行计划。成本的最小单位是随机读取一个4K数据页的成本。可以通过SHOW STATUS LIKE ‘Last_query_cost’查看,结果表示成本单位的倍数。
1‘ 优化器
优化器选择的执行计划不一定是最优的,可能存在以下原因:
- 不考虑并发查询间的影响
- 不考虑不受控制的操作的成本,如存储过程和用户自定义函数
- 有例外规则,如存在全文索引时使用全文索引
- 统计信息不准确,InnoDB的统计信息是估计值
- 优化器计算的成本与实际执行成本和执行时间不同
- 无法估算所有可能的执行计划
2’ 优化策略
优化策略主要分为两类;
静态
直接对解析树分析优化,不因参数变化而变化,相当于编译时优化。如将代数计算转换为WHERE条件
动态
动态优化与上下文相关,需要每次执行前评估
3‘ 优化规则
重新定义关联表顺序
外连接转换内连接
等价变换,简化并规范表达式
如(5=5 and a>5)等价变换为a>5
优化COUNT()、MIN()、MAX()
索引和列非空时可用。如极大和极小只需查找索引端点值即可。
预估并转化为常数表达式
MySQL检测到表达式结果不变或可以转换为常数时直接使用常数。
覆盖索引
子查询优化
转换为效率更高的形式
提前终止查询
条件满足后终止查询,如LIMIT、DISTINCT、NOT EXIST()和LEFT JOIN等存在性判定查询
等值传播
如关联查询中存在关联列上的条件查询,MySQL可以将条件分别应用到两个表中。
列表IN()的比较
MySQL中IN()值先排序再二分查找,而不是像其他关系型数据库中等价于多个OR条件
4‘ 数据和索引的统计信息
信息统计由存储引擎实现。在生成执行计划时,服务器询问表或索引的页面数量、索引基数、数据行和索引长度、索引分布等信息。
5’ 关联查询执行
不论查询涉及的表数量,MySQL将每个查询视为一次关联。
关联通过嵌套循环的形式实现,从上一张表中读取一条记录,循环匹配下一张表的每条记录。
因此,也暗示了MySQL不支持全外连接。
对于UNION,将一系列单个查询结果放入临时表中,再从临时表中读取数据完成UNION操作。
6‘ 执行计划
与其他关系型数据库不同,MySQL生成查询的指令树,通过存储引擎执行指令并返回结果,而不是生成查询字节码。可以通过EXPLAIN EXPAND + SHOW WARNINGS查询重构后的查询,与原查询语义相同。
MySQL的执行计划时一颗左侧深度优先的树。
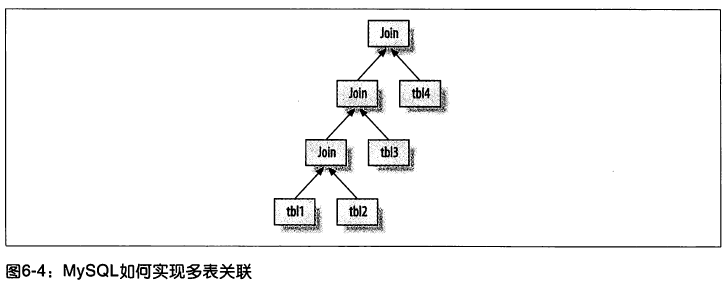
7’ 关联查询优化器
关联查询优化依据成本选择表关联顺序。当关联表数量超过optimizer_search_depth后采用贪婪模式搜索。
使用STRAIGHT_JOIN禁止顺序优化。
8‘ 排序优化
排序是高成本操作,需要避免或者减少数据量。
数据量小于排序缓冲区时,在内存中快速排序;超出时,数据分块到磁盘,采用块内快排+块间归并的方式。
排序算法
(1) 两次传输排序(旧版本)
过程:
- 读取行指针和参与排序的字段进行排序
- 根据排序结果读取数据行
效果:
第二次读取产生大量随机I/O,但是缓存的数据较少。MyISAM使用系统调用实现读取,依赖于操作系统的数据缓冲,受到随机I/O的影响更大。
(2) 一次传输排序(新版本)
过程:
- 读取所有列,按照参与排序的字段排序后直接返回结果
效果:
读取过程是顺序I/O,但是需要占用大量的空间存储数据。
而MySQL在排序时需要为每个字段分配足够长的定长空间用于临时存储。如UTF-8分配3个字节,VARCHAR分配完整长度。
关联查询排序策略
- 如果排序的列均来自关联的第一张表,先排序后关联。Using filesort
- 否则,先关联,并将结果存储到临时表中,再排序.Using temporary;Using filesort
- 最后LIMIT。MySQL 5.6针对LIMIT返回部分结果,会在排序筛除部分结果。
3) 查询执行引擎
执行计划是一种数据结构,而不是和其他关系型数据库一样的字节码。执行引擎逐个执行计划中指令。指令通过调用存储引擎中的“handler API”,向搭建积木一样实现查询。
4) 结果返回
即使无需返回结果,MySQL也会返回如影响行数等的信息。
如果查询可以缓存,可以将结果放置在查询缓存中。
结果返回是一个增量、逐步返回的过程。
每一行以满足通信协议的封包,通过TCP协议发送。传输过程中可能对封包缓存再批量发送。
(4) 查询优化器的局限性
1) 关联子查询
1 | # 原查询 |
注意:在版本8中,已经可以直接使用内层结果优化外层,而之前高效的查询反而更加低效。




注意:关联子查询并不意味着低效,需要通过测试验证性能。如以下可以使用关联子查询避免使用DISTINCT和GROUP BY, 提升性能。
1 | # 原查询 |


注意:其中FirstMatch用于避免重复的查询,在首次查到后即返回,通常用于子查询中。对带有聚合的查询无效。
2) UNION的限制
有时MySQL不能将限制条件“下推”到内层,导致内层查询需要访问更多的行。
1 | # 原查询 |
注意:应用到内层后,加入了排序过程,限制了临时表的容量为40。


3) 索引合并优化
版本>5.0, WHERE子句中存在多个条件时, MySQL能够将单表的多个索引合并或交叉过滤。
4) 等值传递
优化器将IN()列表复制关联到各个表中,以高效过滤记录。但当列表过大时导致优化和执行缓慢。
5) 并行执行
MySQL无法利用多核并行执行。
6) 哈希关联
MySQL所有的关联都是嵌套关联。
Memory引擎支持哈希索引,可以实现类似于哈希关联的形式。
其他引擎可以创建哈希索引以实现哈希关联。
7) 松散索引扫描
MySQL基本不支持松散索引扫描,即不支持不连续地检索索引。
通常可以通过增加索引和枚举前缀索引值的方式实现相同效果。
版本>5.0,可以使用Using index for group-by在查询极值时实现(版本8中没有)。版本>5.6,可以使用索引条件下推实现。
8) 极值优化
1 | # 原查询 |
注意:在MySQL8中优化无效。


9) 在同一表上查询和更新
MySQL不允许在查询表的同时更新表。
1 | # 非法操作 |
(5) 查询优化器提示
HIGH PRIORITY和LOW PRIORITY
控制查询语句在获取表锁的队列中位置。
仅适用于具有表锁的存储引擎,不建议在具有细粒度锁的存储引擎中使用,如InnoDB。
将禁用并发插入,严重降低性能。
DELAYED
立即返回,将插入的行数据放入缓冲区,等待系统空闲时批量写入。
适用于客户端无需等待的日志系统或者大量数据写入。
仅部分存储引擎支持,影响函数LAST_INSERT_ID()。
STRAIGHT_JOIN
按照语句顺序关联表。
SQL_SMALL_RESULT和SQL_BIG_RESULT
指定临时表位置, 前者在内存中,后者在磁盘中。
仅对SELECT有效。
SQL_BUFFER_RESULT
将查询结果缓存到服务器内存中的临时表,以尽快释放表锁。
SQL_CACHE和SQL_NO_CACHE
是否缓存结果集到查询缓存中
SQL_CALC_FOUND_ROWS
计算不带LIMIT的结果集容量,可以通过FOUND_ROWS()查看。
FOR UPDATE和LOCK IN SHARE MODE
控制SELECT语句的锁机制。
仅对具有行锁的存储引擎有效。
影响优化,如覆盖索引扫描。不建议使用。
USE INDEX、IGNORE INDEx和FORCE INDEX
指定查询使用的索引,FROCE更偏向使用索引。
FOR ORDER BY和FOR GROUP BY可指定用途
版本>=5.0,新增优化器参数:
optimizer_search_depth
穷举执行计划时的限度。如查询长时间处于“Statistics”时可用。
optimizer_prune_level
根据扫描行数取舍执行计划,默认开启。
optimizer_switch
控制优化器特性,如索引合并等。
注意:可以使用Percona Toolkit中的pt-upgrade工具检查数据库新旧版本是否返回结果一致。
(6) 特定类型查询优化
1)COUNT()
作用是统计非空列值数量或行数。
统计列值:指定了列或表达式,不统计NULL
统计行数:列值或表达式非空,如COUNT(*)
1’ MyISAM
当且仅当统计没有条件限制的行数时,可以直接读取存储引擎保存的统计值。
2‘ 简单优化
1 | # 一、MyISAM中减少扫描行数 |
3’ 使用近似值
在不要求精确统计的场景中可以使用成本更小的近似值替代。
- EXPLAIN中的扫描行数
- 去掉约束条件或去重条件后的查询结果,提升查询性能和避免文件排序
4‘ 复杂优化
快速、精确和简单,只能同时选择两个。
- 覆盖索引扫描
- 汇总表或者类似memcached的外部缓存系统。
2) 关联查询
- 确保第二个表的关联列上有索引,多余的索引带来额外的负担。
- GROUP BY和ORDER BY只涉及其中一张表,以便优化。
- 升级时,考虑前后版本关联语法、运算符优先级等变化。
3) 子查询
版本<5.6,尽量使用关联查询替代。
4) GROUP BY和DISTINCT
在MySQL内部,两者可以相互转换。
1’ 使用索引
2’ 临时表或文件排序
在无法使用索引时,同城使用临时表或文件排序实现。
- SQL_SMALL_RESULT提示内存排序,SQL_BIG_RESULT提示磁盘排序
- 使用主键分组更加高效
1 | # 原查询 |


3’ 排序优化
没有使用ORDER BY显式指定排序列而直接使用GROUP BY时,默认将结果集按照分组列排序。
- 使用ORDER BY NULL取消排序
- 可以直接在GROUP BY中通过ASC或DESC指定排序顺序
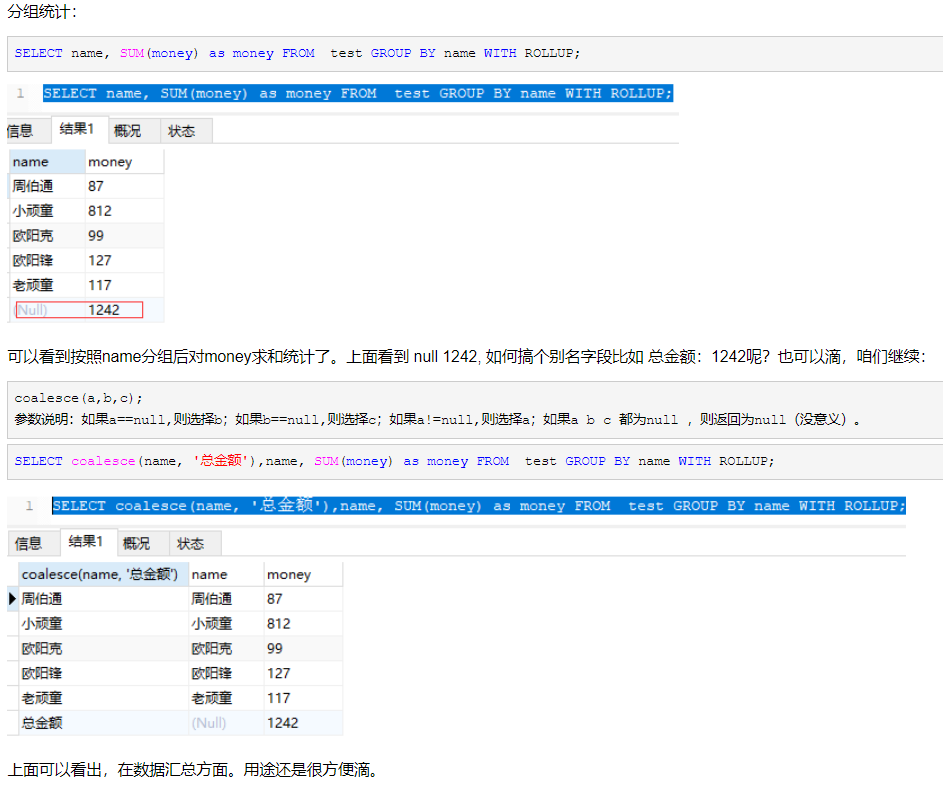
4‘ GROUP BY WITH ROLLUP
WITH ROLLUP要求MySQL对分组结果执行超级聚合。
超级聚合:在分组的基础上统计,如按照姓名分组,再统计总金额。
出于性能的考量:
- 尽量将超级聚合转移到应用程序中处理
- FROM字句中嵌套使用子查询
- 临时表中存储中间结果,UNION获得最终结果
5) LIMIT
通常使用LIMIT + 偏移量 + ORDER BY。但在没有索引的情形下需要大量的文件排序操作。
- 索引覆盖扫描+延迟关联
- 计算索引列范围区间
- 保存检索位置
- 汇总表
- 冗余表(只包含主键和排序列)
- Sphinx搜索优化
1 | # 原查询 |
原查询、延迟关联和保存位置:



6) SQL_CALC_FOUND_ROWS
版本8.0.17标记弃用。
通常用于统计没有LIMIT限制的结果集大小。实际仍然需要扫描满足条件的所有行,不能减少扫描行数。
1 | # 原查询 |
优化:
- 多查一行。如果达到阈值则可以翻页。
- 多查多行。在缓存中翻页。
- 使用EXPLAIN中的函数作为结果集近似大小。
7) UNION
UNION会添加DISTINCT作唯一性检查,代价较大。
没有去重需求,尽量使用UNION ALL。
8) 静态查询分析
Percona的pt-query-advisor可以对查询进行健康检查。包括解析查询日志、分析查询模式、列出潜在问题。给出详细建议等。
9) 用户自定义变量
是用于存储内容的临时容器。
1‘ 限制
- 使用自定义变量的查询,无法查询缓存
- 不能使用自定义变量替代常量或标识符,如表名、列名和LIMIT子句
- 生命周期仅限于当前连接
- 在使用连接池或持久化连接时可能代码结果混乱
- 版本<5.0时,大小写敏感
- 不能显式声明类型,可以在初始化时通过值指定
- 可能被优化器去除
- 赋值时间和顺序不确定,依赖于优化器
- 赋值符号:=优先级低
- 使用未定义变量不会报错
2’ 优化排名语句
注意变量赋值的时间不确定,可以拆分查询避免混乱。
1 | #使用用户定义变量辅助排序 |
注意:
- rank在版本8中是关键字,不能用于别名
- 提取的表需要命名,如der


3‘ 获取更新的数据
MySQL原生不支持返回更新的数据。
1 | # 原查询 |
4’ 统计更新和插入的行数
MySQL自动返回行数,无需如下操作。
1 | # 更新时@x自增,乘0避免对值产生影响 |
5’ 确定取值顺序
为了避免意料之外的行为,变量的赋值和读取需要在查询的同一阶段。
1 | # 混乱查询 |
6‘ 分支选择
用于从冷热数据表中选择其一进行查询,另一表通过设置的变量“跳过”。
通常用于对冷热数据和在线、归档数据查询。
1 | # 原查询 |
7’ 其他用处
- 运行时计算总数和平均值
- 模拟GROUP语句中的FIRST()和LAST()函数
- 数据计算
- 计算大表的MD5散列值
- 计数
- 模拟读写游标
4 案例学习
(1) 队列表
在高流量、高并发场景下,更新不同的记录处理状态。通常用于邮件发送、多命令处理和评论修改等系统。
最好将相应的任务队列从数据库中迁移出来。如使用Redis、memcached等内存存储,Q4M存储引擎或RabbitMQ、Gearman等消息队列。
队列表任务:
- 将已处理记录归档
- 将标记处理中的记录
1 | # 阻塞线程 |
(2) 计算两点之间的距离
不建议使用MySQL进行复杂的空间计算,可选PostgreSQL。
1 | # 查找某点半径范围内的点 |
注意:
- Sphinx具有由于MySQL的地理信息搜索功能
- MyISAM虽然具有GIS函数, 但是其自身不适合于大数据量和高并发应用,并且具有表级粗粒度锁和数据文件崩溃等缺点
(3) 用户自定义函数
对于MySQL难以应对的场景,可以使用用户自定义函数UDF。可以使用其他语言或框架实现,运行在服务器上,通过简单的网络通信协议与MySQL交互。
5 小结
优化原则:不做、少做和快速地做。
参考资料
《高性能MySQL》