1 流程
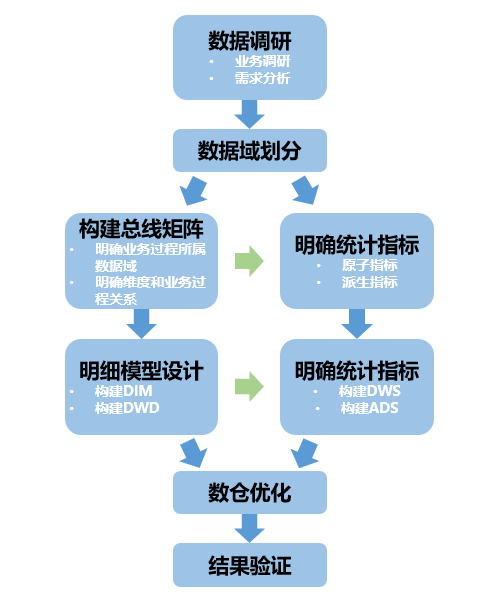
整体流程:
- 数据调研
- 数据域划分
- 构建总线矩阵
- 明细模型设计
- 数仓优化
- 结果验证
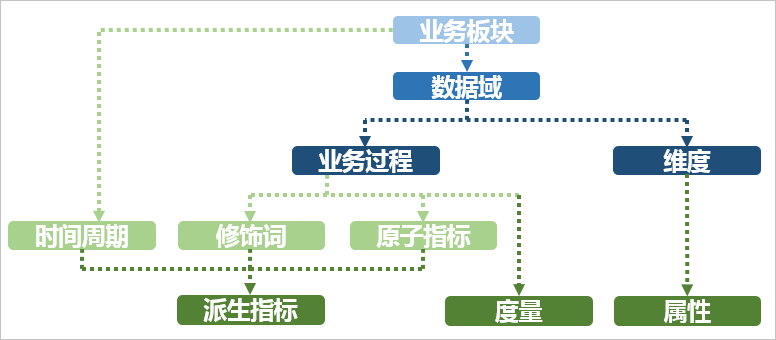
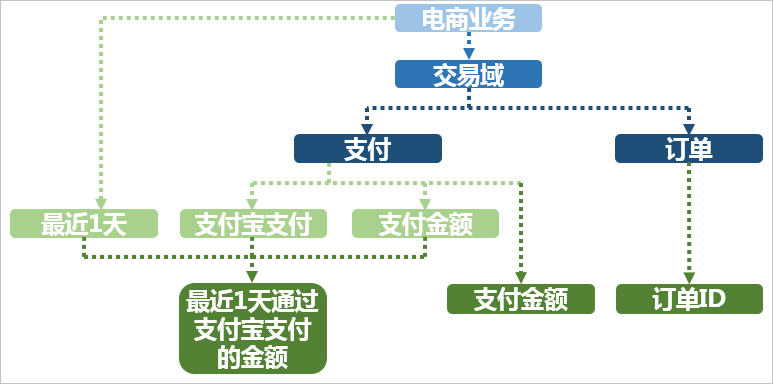
基本概念:
业务板块:数据域是一个独立业务流程,业务板块是相关数据域的集合。
维度:度量(事实)的环境信息,也可以称为实体对象。如交易流程中,使用买家、卖家、商品和交易时间等描述交易发生的环境。
属性(维度属性):维度的列。用于约束和分组等,是数据易用性的关键。
指标:分析的实体。分为原子指标和派生指标。
原子指标
业务过程+度量
某一业务事件行为下的度量,不可再分,是具有具体业务意义的名次,如支付+金额。
派生指标
具有限定条件的业务指标。
时间周期+修饰词+原子指标,如最近一天+支付宝+支付金额
业务限定:记录的筛选条件,除时间区间外
- 统计周期:选中记录的时间区间
- 统计粒度:数据汇总的程度,如聚合函数的分组区间大小。
2 业务调研
充分的业务调研和需求分析是数据仓库建设的基石。
(1) 确定需求
通过调查表、访谈等形式详细了解以下业务信息:
- 用户的组织架构和分工界面。不同的业务部门有不同的需求。
- 整体业务、业务模块及相互联系和数据流动,用于梳理业务数据框架。
- 业务系统的主要功能及获取的数据。
通过沟通和现有报表获取数据分析和运营的数据需求。
思考分层、指标及粒度:
- 汇总依据的维度或粒度、衡量标准,如成交量是维度,订单数是成交量的度量。
- 原始细节级、汇总细节级、公共维度层设计,公共指标取舍
- 汇总细节级数据冗余取舍
(2) 分析业务流程
业务过程是不可拆分的事务单位。
使用过程分析法,梳理业务过程中的环节,获取数据信息:
- 每个环节产生的数据和内容,存储的位置
- 数据更新的逻辑
明确业务过程后,可以根据分析决策需求划分数据域。
(3) 划分数据域
数据域是数据主题的集合,是业务过程或维度的抽象集合,用于数据管理和应用。
要求数据域既能满足当前需求,又能满足未来的业务需求。
通常可以按照部门或者功能模块划分。
如商品、日志、交易、服务等
(4) 定义维度与构建总线矩阵
1) 定义维度
要求全局唯一
2) 构建总线矩阵
维度和业务过程的映射,即维度是否在特定事实中出现
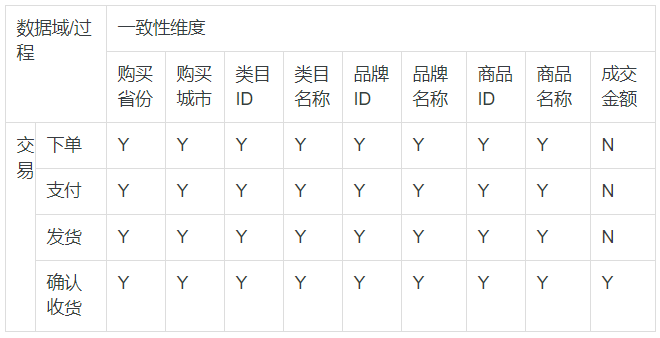
(5) 明确统计指标
1) 注意事项
原子指标=业务过程+度量
派生指标=时间周期+修饰词+原子指标
- 原子指标、修饰类型和修饰词直接归属于业务过程。其中修饰词继承修饰类型的数据域。
- 派生指标晚于原子指标创建,如支付金额为原子指标,客单价(支付金额与买家数的比值)为派生指标
- 派生指标唯一归属于一个原子指标,继承原子指标的数据域,与修饰词数据域无关
2) 指标确定

3 架构与模型设计
(1) 技术架构选型

DataWorks负责数据采集和基本ETL、数据开发、数据质量、数据安全和数据管理。
MaxCompute负责离线数据计算
(2) 数仓分层

数据引入层ODS
从业务系统同步数据,转换为结构化数据,并清洗
CDM
维度表DIM+公共汇总层DWS+明细事实表DWD
ADS
个性化指标机构和应用数据组装
(3) 数据模型
1) 公共维表层DIM
考虑因素
- 数据稳定性:直接更新,还是保留历史
- 查询变慢->是否垂直拆分
- 记录过多->是否水平拆分
主要步骤:
- 初步定义,保证唯一性
- 确定主维表(中心事实表),通常采用星型模型、直接与业务系统同步
- 确定相关维表
- 确定维度属性
2) 数据引入层ODS
原始细节数据,注意区分更新方式和来源等
1’ 存储
1‘‘ 增量存储
适合总量大,全体扫描少的场景,如日志、交易等
2’’ 全量存储
适合体量小,变化慢的场景
3‘‘ 拉链存储
通过增加生效和失效两个时间字段,控制数据的状态
2‘ 缓缓慢变化维度
1’‘ 快照
存在空间浪费,需要设置数据生命周期
2’‘ 代理键
用于关联维表和事实表,如序号
保证全局唯一的开发、维护成本高
3’‘ 直接覆盖原值
缺乏历史信息
3‘ 数据同步加载与处理
使用DataWorks数据集成功能完成数据同步
规范:
- 一个系统的源表值允许同步到MaxCompute一次,保持表结构的一致性
- 全量同步的数据进入当日分区
- ODS层建议以统计日期和时间分区表的方式存储,遍历数据管理
- 数据集成自动添加目标表中不存在的字段,设置源表中不存在的字段为NULL
3) 明细粒度事实层DWD
1’ 定义
最细粒度的事实层,可以冗余部分重要维度属性(宽表化处理)。
公共汇总粒度事实层DWS和明细粒度事实层DWD的事实表作为数据仓库维度建模的核心。
2‘ 事实
事实通常为数值型,分为可加性、半可加性和完全不可加性:
- 可加性:可以在任意维度相加,如支付金额;
- 半可加性:只能在特定维度上相加,如库存,可以按照地点和商品汇总,不能按照时间汇总;
- 完全不可加性:不能相加,如客单价等比值型数据,但可以分解为可加的组件聚集。
3’ 事实表
维表退化:在事实表中添加维度属性,可以加速查询,便于过滤聚合。
明细粒度事实层DWD通常分为三种:
- 事务事实表(原子事实表):用于描述业务过程,保存最原子的数据
- 周期快照事实表:按照一定时间间隔记录的事实
- 累积快照事实表:用于表述开始和结束之间的关键事件。通常具有多个时间字段。
4‘ 设计原则
命名规范:dwd{业务板块/pub}{数据域缩写}{业务过程缩写}[{自定义表命名标签缩写}] _{单分区增量全量标识}
1’‘ 选择业务过程
2’‘ 确定粒度
- 在维度和事实选择前声明粒度
- 同一事实表中粒度统一
3’‘ 选择维度
- 通常一个明细事实表仅和一个维度关联
4’‘ 确定事实(度量)
- 只包含与业务过程相关的事实
- 尽可能包含所有与业务过程相关的事实
- 分解不可加事实为可加组件
- 单位统一
- 谨慎处理NULL
- 维度退化增加事实表可用性
4) 公共汇总粒度事实层DWS
以分析的主题对象作为建模驱动,基于上层应用和产品的指标构建。通常对应一个派生指标
1’ 设计原则
- 数据公用性:是否公开
- 不跨数据域
- 区分统计周期
2’ 规范
命名规范:dws{业务板块缩写/pub}{数据域缩写}{数据粒度缩写}[{自定义表命名标签缩写}]_{统计时间周期范围缩写}
(4) 层次调用规范
原则:
- 应用层不能直接调用接入层,必须通过公共层。防止数据重复计算、不合理复制和子集合冗余
- 公共层深度不宜过大,控制在10层以内
- 通常一个计算刷新任务只允许输出一个表
- DataWorks中多个任务输出到同一表,中间需要插入一个虚拟任务。
- 数据调用就近
4 项目分配与安全
接入层、公共层按照业务板块划分项目,应用层按照应用划分项目
(1) 项目分配
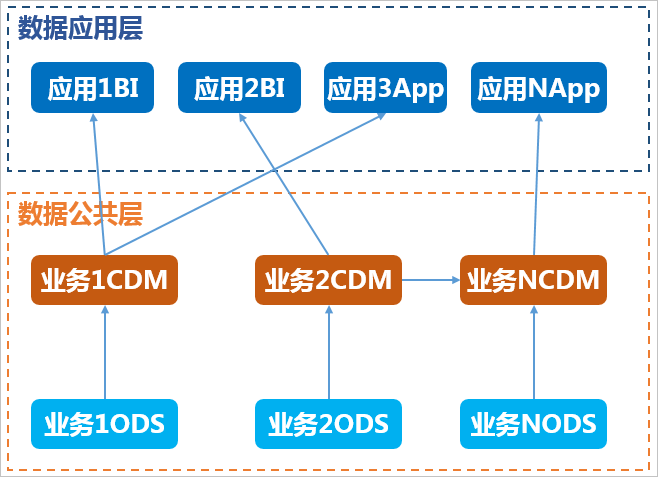
(2) 项目模式选择
DataWorks标准模式实现了生产和开发环境的隔离,保证生产环境中的数据安全。
(3) 项目权限配置
详见安全模型
5 建立性能基准
MaxCompute性能表现取决于设计的规范性。通过数据同步时间、占用存储大小和查询性能衡量。
6 数仓性能优化
(1) 哈希聚集
使用CLUSTER BY指定哈希聚集的列,可以在分组、聚合和存储时优化。
1 | ALTER TABLE table_name [CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS] |
注意:
- 只能通过INSERT OVERWRITE添加
- 不能使用tunnel upload导入数据,因为数据无序
(2) 其他优化
- 中间表:用于数据量大,下游表多
- 拆表:用于字段间更新速率明显不同
- 合表:用于消除冗余
- 拉链表:用于减少存储占用
- 利用MapCompute表的特殊功能
7 结果验证
确认数仓优化的有效性