1 基础
<=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或都为 NULL 时返回 true。
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
修改表ALERT
1 | # NULL值缺省为允许NULL |
2 事务
事务控制语句:
- BEGIN 或 START TRANSACTION: 显式开启一个事务;
- COMMIT 或COMMIT WORK:等价的。COMMIT 会提交事务,并将所有修改成为永久性的;
- ROLLBACK 或 ROLLBACK WORK:等价的。回滚会结束用户的事务,并撤销所有未提交的修改;
- SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;可用于标记当前事务状态,再嵌套事务过程。
- RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
- ROLLBACK TO identifier 把事务回滚到标记点;
- SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
MYSQL 事务处理主要有两种方法:
1、用 BEGIN, ROLLBACK, COMMIT来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
2、直接用 SET 来改变 MySQL 的自动提交模式:
- SET AUTOCOMMIT=0 禁止自动提交
- SET AUTOCOMMIT=1 开启自动提交
3 索引
索引能提高查询速率,同时也降低了更新速率。
1 | #BLOB或TEXT必须指定length |
4 临时表
仅在当前会话中可用的表。使用同普通表,但是不能使用SHOW TABLES查询
1 | # 创建 |
5 复制表
CREATE TABLE SELECT只能复制表结构和数据、NULL约束等,不能复制索引、默认值等其他约束和触发器,会提交当前未完成的事务,整个过程占用元数据锁,不被基于GTID的复制支持。
1 | # 方法一 |
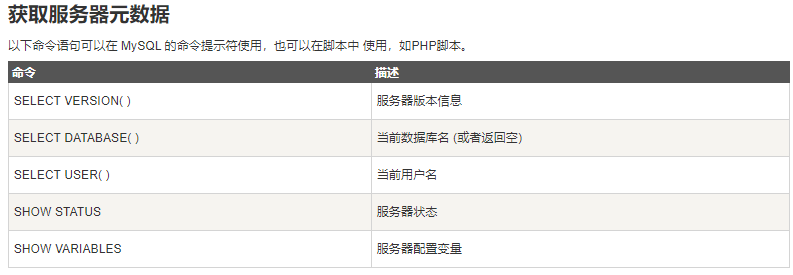
6 元数据
7 序列
即AUTO_INCREMENT
1 | # 使用 |
8 重复数据
(1) 防止重复数据
使用主键PRIMARY KEY或唯一索引UNIQUE
(2) 统计重复数据
GROUP BY分组,COUNT计数,HAVING过滤出重复数据
1 | SELECT COUNT(*) as repetitions, last_name, first_name |
(3) 过滤重复数据
1 | # DISTINC |
(4) 删除重复数据
1 | # 方法一:将所有字段作为分组依据,过滤重复数据并新建表、删除原表 |
9 SQL 注入
1.永远不要信任用户的输入。对用户的输入进行校验,可以通过正则表达式,或限制长度;对单引号和 双”-“进行转换等。
2.永远不要使用动态拼装sql,可以使用参数化的sql或者直接使用存储过程进行数据查询存取。
3.永远不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
4.不要把机密信息直接存放,加密或者hash掉密码和敏感的信息。
5.应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装
6.sql注入的检测方法一般采取辅助软件或网站平台来检测,软件一般采用sql注入检测工具jsky,网站平台就有亿思网站安全平台检测工具。MDCSOFT SCAN等。采用MDCSOFT-IPS可以有效的防御SQL注入,XSS攻击等。
10 数据导出
(1) SELECT … INTO OUTFILE
用户需要具有读取数据和文件写入的权限
不能使用已有的文件,为了避免数据被修改。
在Unix中,文件可读且所有者为MySQL所有者。
1 | SELECT |
(2) mysqldump
生成建表脚本
1 | # --tab指定文件目录 |
11 数据导入
1 | # 方法一: mysql命令 |

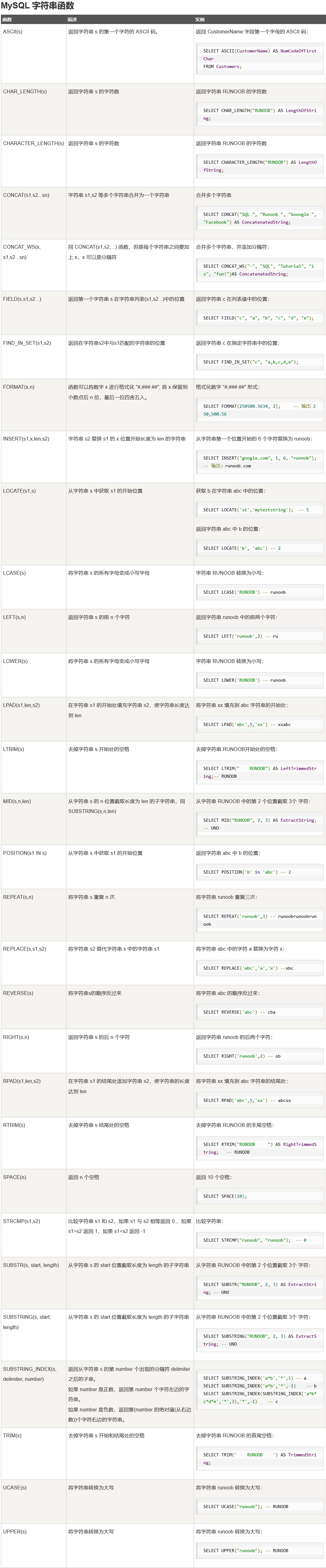
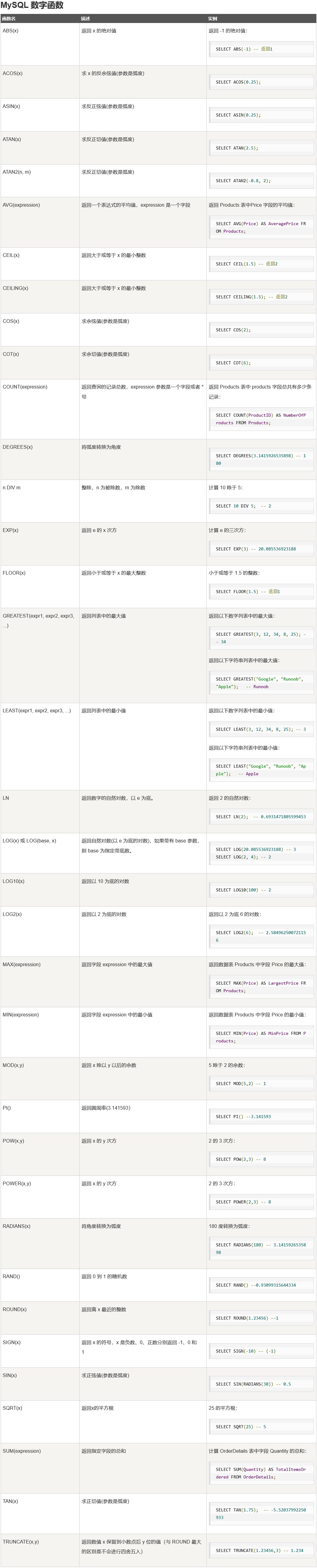
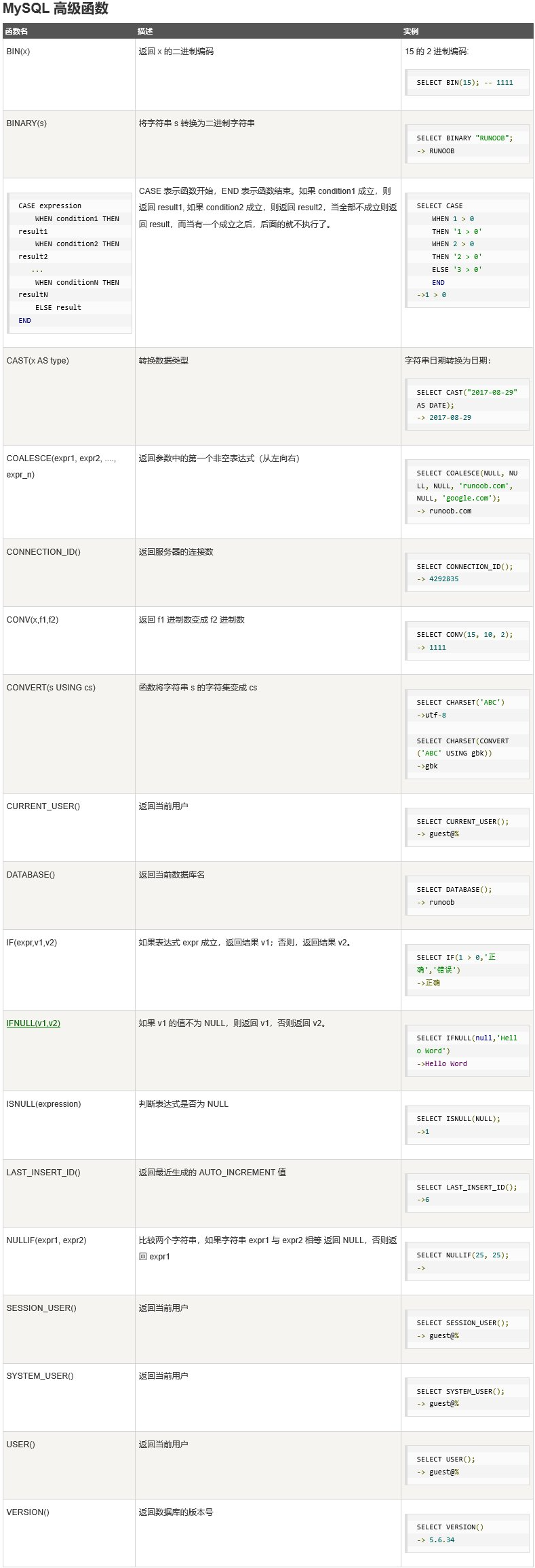
12 函数

13 运算符
安全等于<=>:严格比较两个值是都均为NULL,是则返回1,其中一个是返回0
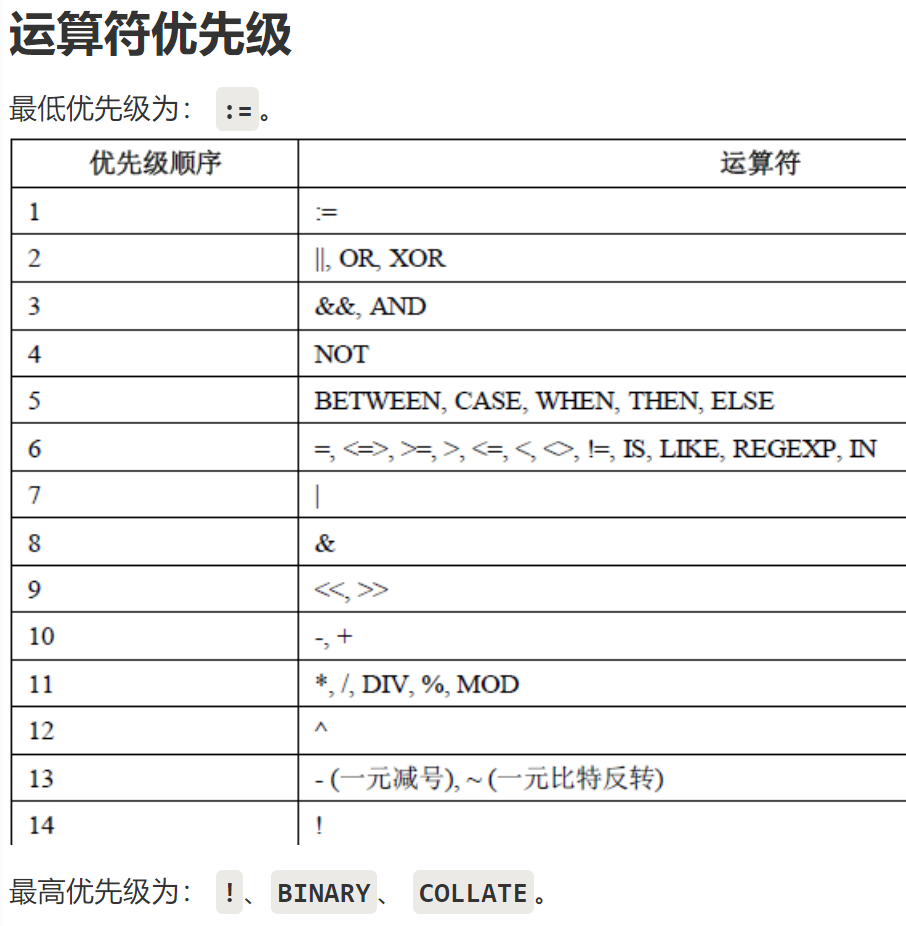
优先级:从上到下依次增重