1 概览
Structured Streaming提供快速、弹性、容错、端到端刚好一次保证的流式处理。
延迟可低至100ms
版本>=2.3, 引入持续处理,延迟低至1ms,提供至少一次语义。
2 示例
1 | import org.apache.spark.sql.functions._ |
3 编程模型
Spark SQL可以理解为在一个静态数据集中执行批处理,而Structured Streaming是在一个无限表中增量查询。
(1) 基本概念
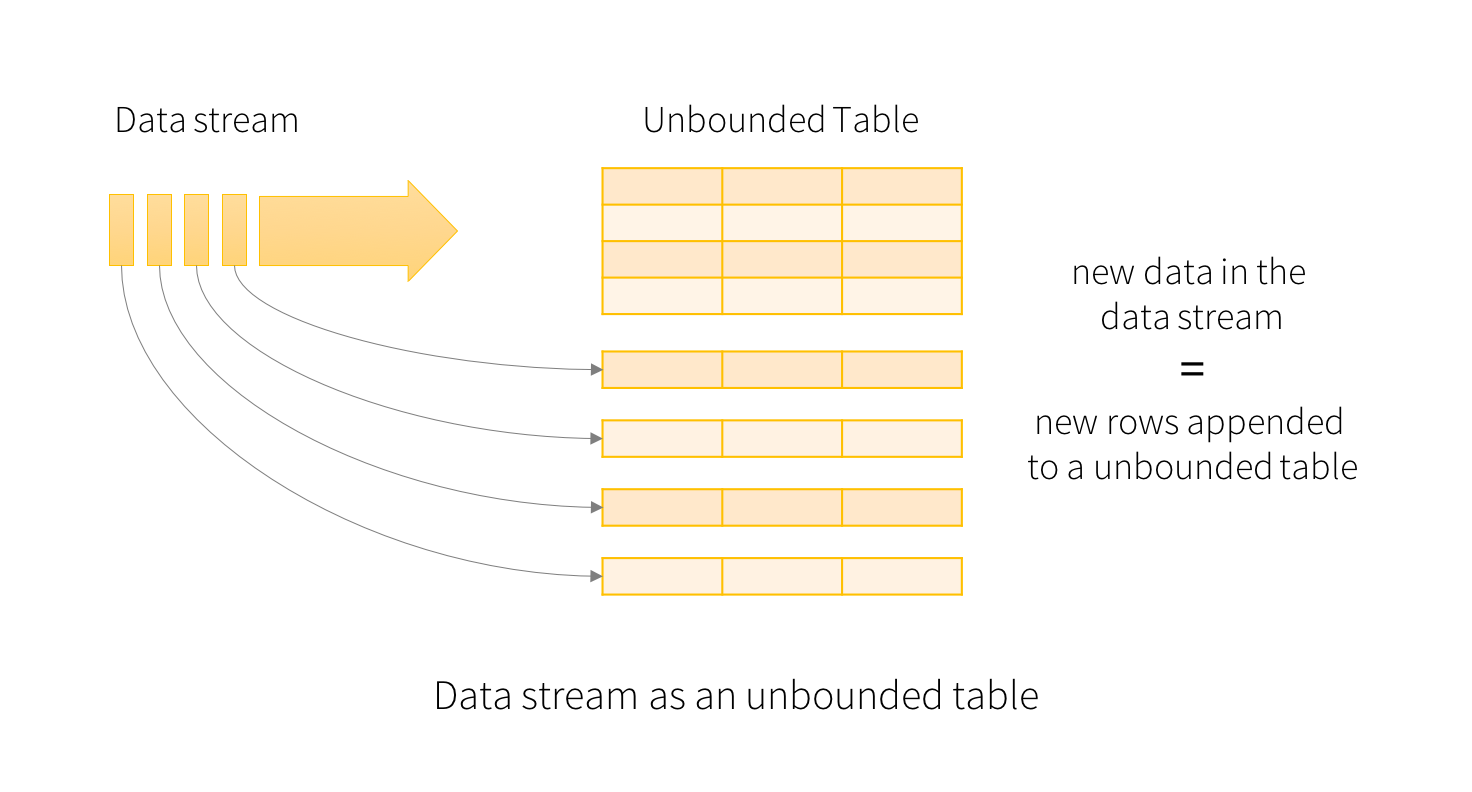
数据流中的每条记录相当于添加到表的一个新行。
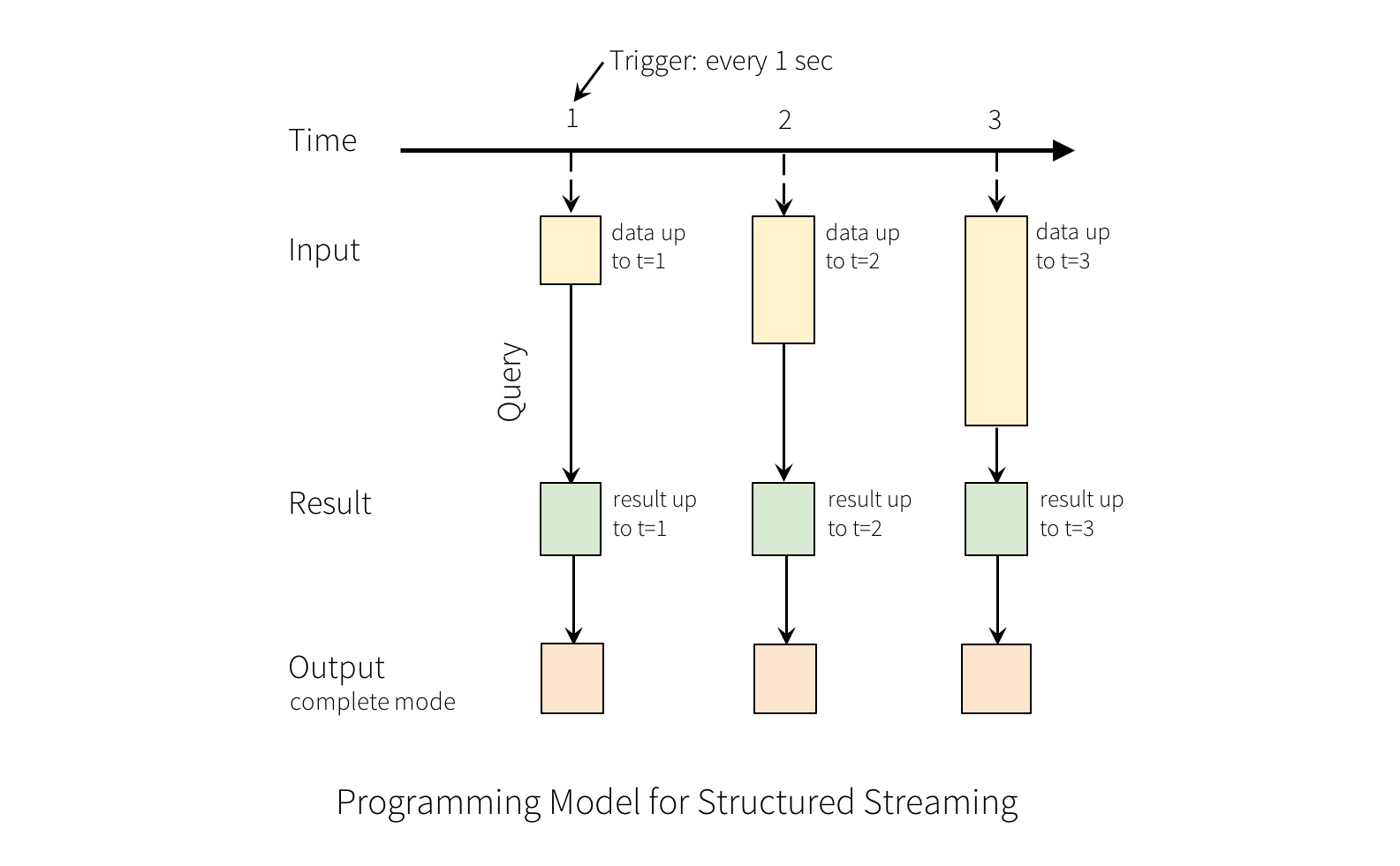
每隔触发时间(1s),新行被添加到输入表中。将被输出到外部存储中。
输出有三种模式:
- 完全:输出整个表
- 追加:仅输出当前触发间隔新增的行,前提是之前的数据不会改变。
- 更新:版本>=2.1.1,仅处理更新的行。如果没有聚合操作,等价于追加模式。
注意:Structured Streaming不会物化输入表。与其他流式处理程序不同,其只保留用于更新结果的最少的中间状态数据。
(2) 处理事件时间和晚到数据
事件时间数据包含在流式记录中,可用于窗口操作。
对于相比时间事件晚到的数据,Spark可以清除之前的聚合状态,重新聚合。
版本>=2.1,Spark提供水印用于限制晚到数据的阈值。
(3) 容错语义
Structured Streaming提供端到端刚好一次语义。
通过使用类似Kafka偏移的机制跟踪数据流读取位置,使用检查点和预写日志记录每个触发的记录偏移范围。输出过程设计为幂等。
4 使用Dataset和DataFrame API
版本>=2.0,可以直接通过SparkSession,使用流式数据源创建Dataset/DataFrame。
(1) 创建流式Dataset和流式DataFrame
使用SparkSession.readStream()创建流式DataFrame。
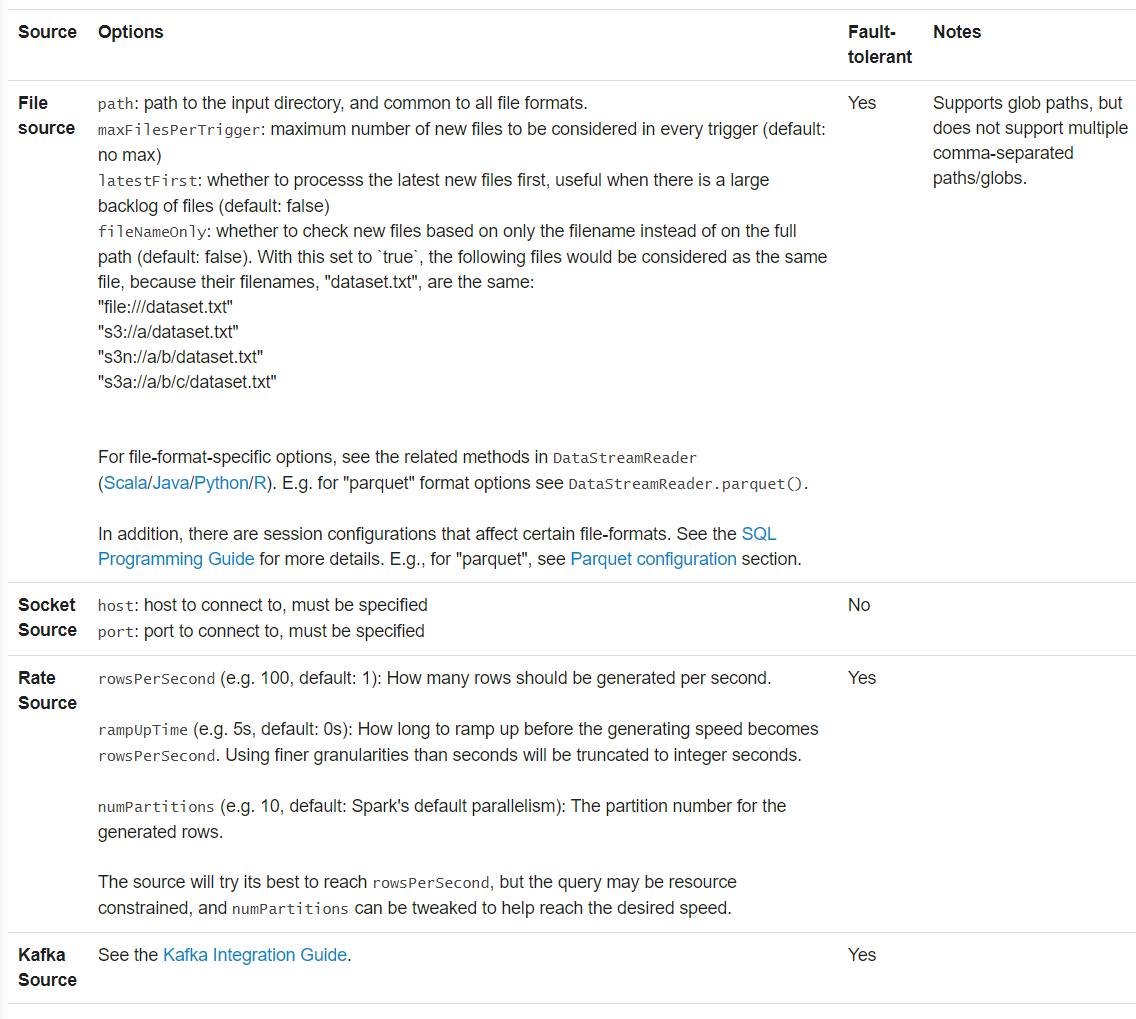
1) 输入源
内置数据源:
文件
将目录中的文件作为流式记录。
支持text/csv/json/orc/parquet等格式,详见DataStreamReader接口
注意文件必须原子性地放置在目录中
Kafka
适用于Kafka版本>=0.10
套接字
测试用,监听驱动节点接口,接收UTF-8文本。不提供端到端容错。
频率
测试用,按照指定的每秒行数更新数据,每个输出行中包含timestamp(时间戳类型,消息分发时间)和value(长整型,消息计数,从0开始)
1 | val spark: SparkSession = ... |
以上更新的流式DataFrame是无类型的,即编译时不检查模式,只在提交提交查询时检查。
map、flatmap的需要编译时检查模式,可以采用同静态DataFrame的方式。
思考:有类型与无类型区别是类SQL和类RDD?
2) 模式推断和分区发现
为了保证一致的模式,默认使用文件数据源时,需要指定模式。对于临时查询,可以启用, spark.sql.streaming.schemaInference->true
分区发现自动检测命名类似/key=value/的子目录。查询开始后,需要保证相关的子目录不变。
(2) 操作流式Dataset和流式DataFrame
可以使用流式Dataset/DataFrame的类SQL操作和有类型的类RDD操作,
1) 基本操作:选择、投影和聚合
1 | case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime) |
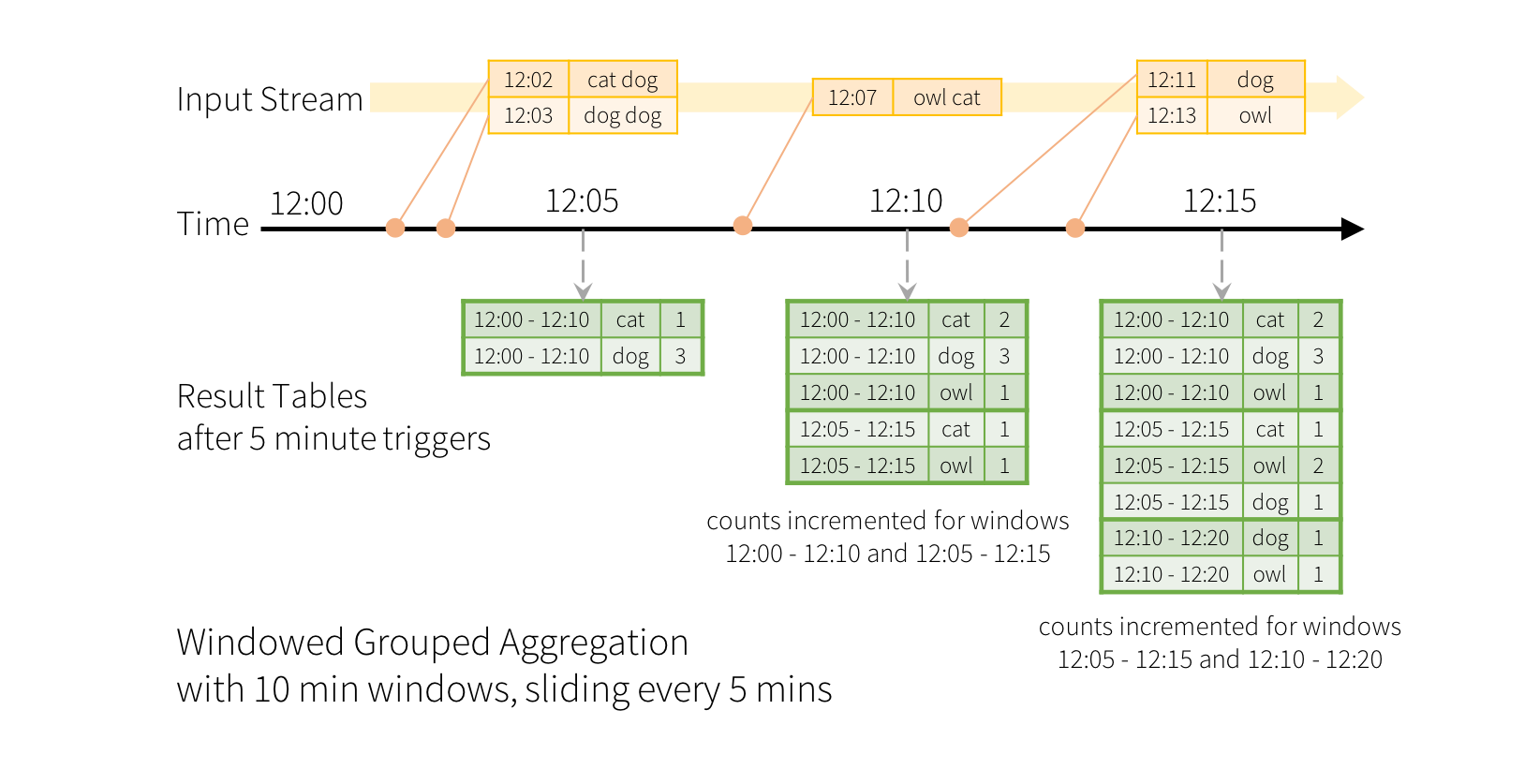
2) 事件时间窗口操作
示例:以10分钟批处理时间和5分钟滑动间隔,计数接收的单词数量
1 | import spark.implicits._ |
1’ 处理晚到数据和水印
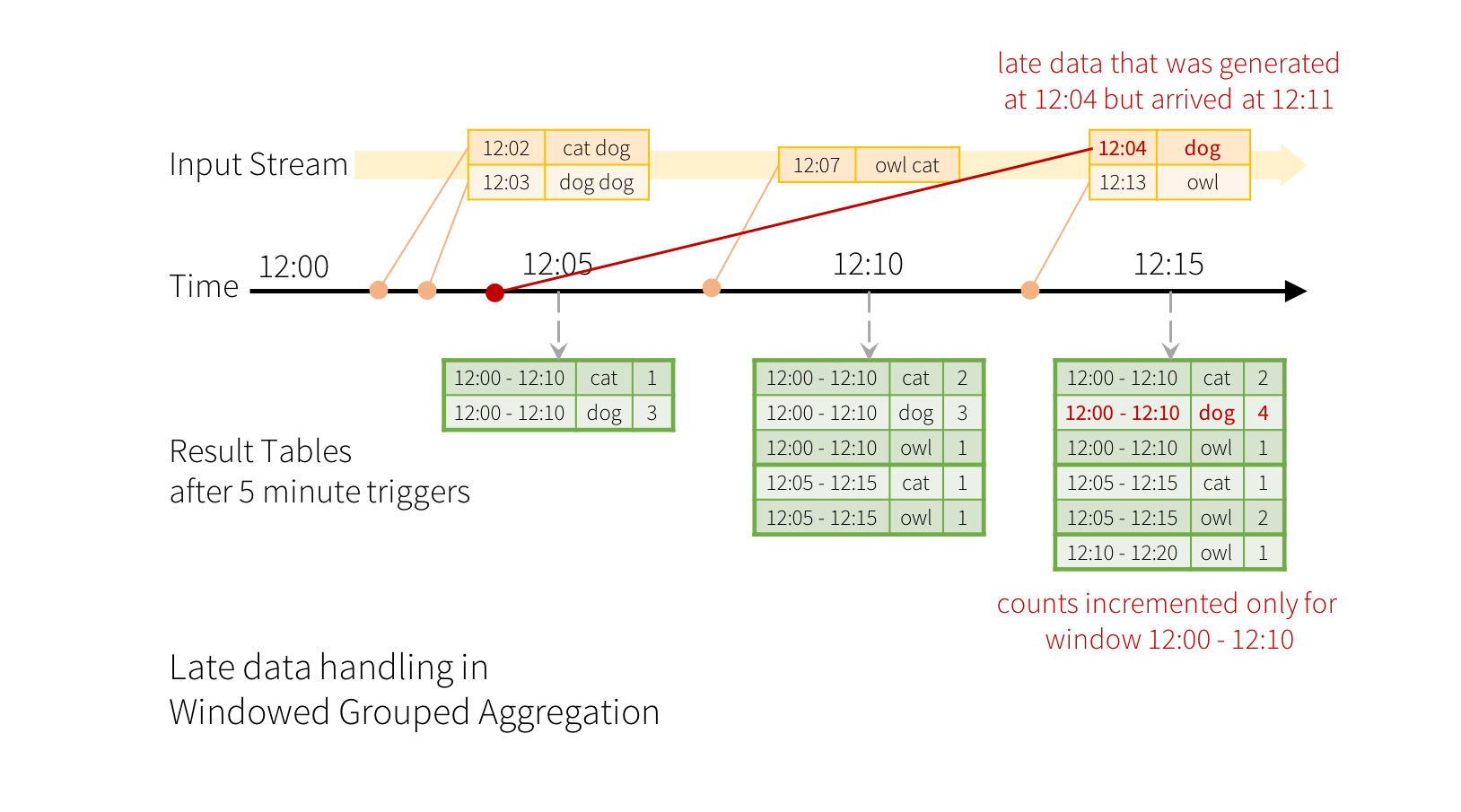
Structured Streaming为部分聚合长时间维持中间状态,以处理晚到数据。
版本>=2.1,Spark使用watermark设置晚到数据的容纳时间间隔,超出则丢弃。
1 | val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String } |
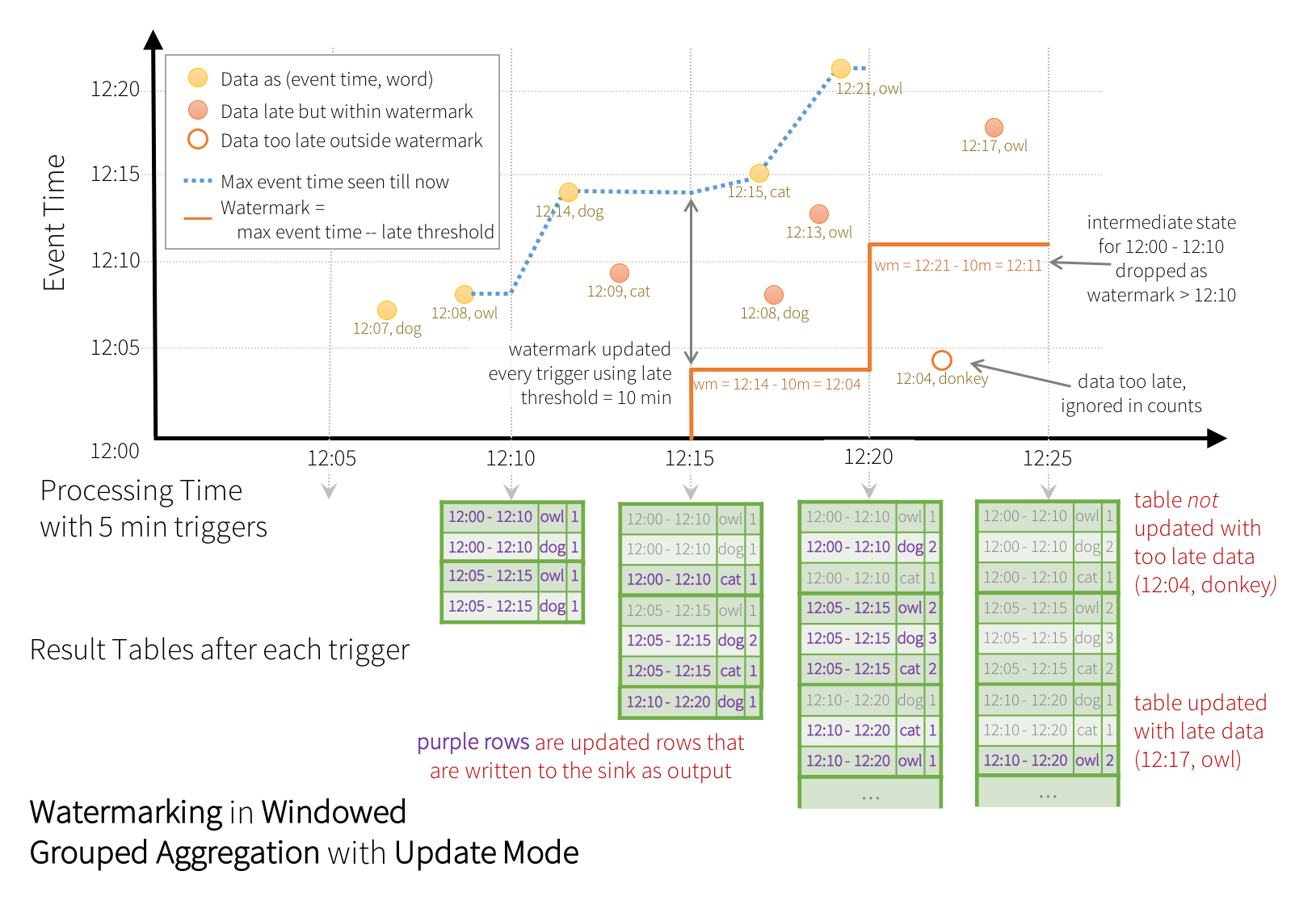
窗口中最大的事件时间,延后水印时间间隔,即为有效的数据更新范围。
由于部分输出不支持细粒度(如文件),可使用追加模式将最终状态输出。
withWatermark对非流式Dataset无意义。
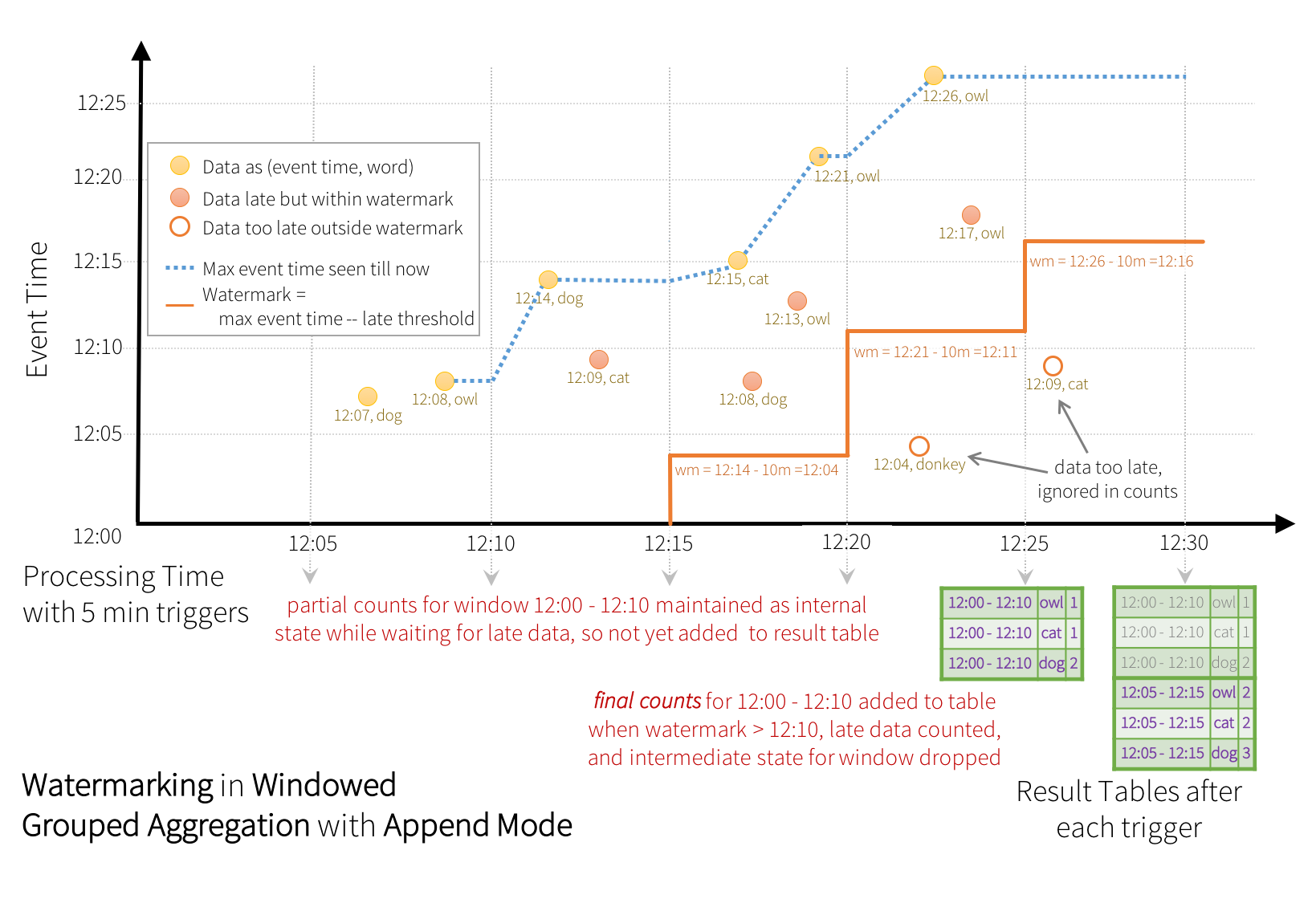
更新模式在超出水印时间后,才将最终结果输出到结果表中。
水印清理聚合状态条件:(版本2.1.1,后续可能有更新)
- 输出模式只能是追加或更新,因为完全模式不需要。
- 聚合必须有事件时间列或者在事件时间列上窗口操作
- 调用withWatermark和聚合操作的列必须是同一列。 如df.withWatermark(“time”, “1 min”).groupBy(“time2”).count()非法
- 调用withWatermark在聚合操作之前,因为需要使用水印信息。
使用水印的聚合操作的语义保证;
两小时内保证处理
不保证删除延迟超过两小时的数据。
However, the guarantee is strict only in one direction. Data delayed by more than 2 hours is not guaranteed to be dropped; it may or may not get aggregated. More delayed is the data, less likely is the engine going to process it.
3) 连接操作
对于支持的连接类型,如同静态Dataset/DataFrame一样。
1‘ 与静态连接
流式与静态连接。支持内连接和部分外连接。
无状态,不需要状态管理
1 | val staticDf = spark.read. ... |
2’ 与流式连接
问题是如何处理晚到数据,满足未来数据的需求。
Structured Streaming缓存过去输入数据作为流式状态,使用水印处理晚到数据。
1‘’ 使用可选水印内连接
支持使用任意列在任意条件下内连接。
为了避免无限的中间状态,需要进行以下设置:
水印
连接的时间范围
时间范围
如JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR
事件时间窗口
如JOIN ON leftTimeWindow = rightTimeWindow
1 | import org.apache.spark.sql.functions.expr |
语义保证
同流式聚合,2h类保证处理,超过2h不保证
2‘’ 使用水印外连接
为了更新NULL结果,引擎必须知道用于匹配的输入数据范围,必须使用水印。
1 | impressionsWithWatermark.join( |
语义保证同内连接
注意:
- 更新时间取决于水印和时间条件
- 在当前的微批处理中,水印在批处理最后更新。下一批处理使用更新后的水印清除状态和输出结果。当其中一个连接的流没有后续数据时,外连接输出可能延后。
3‘’ 连接支持
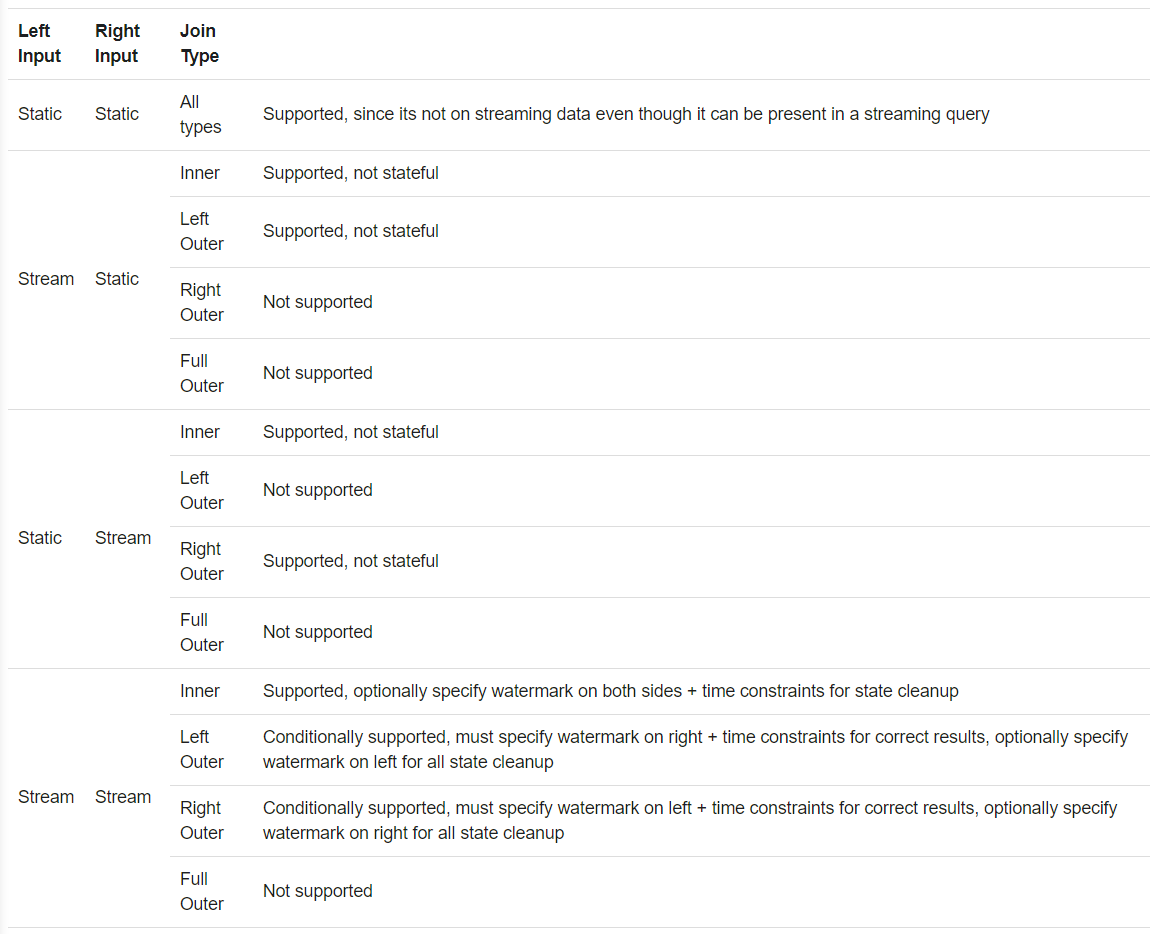
思考:
- 有输入流场景下,均不支持全外连接
- 流+ 静态,静态一侧不支持
注意:
- 连接可以层叠,如df1.join(df2, …).join(df3, …).join(df4, ….)
- 对于2.3,连接操作只支持追加输出模式
- 对于2.3,在连接前,不能使用非类似map操作,如流式聚合和状态转换(mapGroupsWithState和flatMapGroupsWithState)
4) 去重
通常使用唯一标识符去重,可以选择是否使用水印辅助去重:
使用
超过水印时间的过去状态被移除
不使用
保存所有过去状态
1 | val streamingDf = spark.readStream. ... // columns: guid, eventTime, ... |
5) 任意状态操作
支持保存任意类型的数据作为状态,并在每个触发中使用事件作任意操作。
使用mapGroupsWithState和flatMapGroupsWithState接口
详见API documentation (Scala/Java) 和examples (Scala/Java)
详见API documentation (Scala/Java)和(Scala/Java)
6) 不支持操作
- 多个流聚合
- limit和前N条
- distinct
- 排序只在聚合后的完全输出模式
- 部分外连接
由于部分静态操作立即查询并返回结果,因此不被支持,需要转换为流式操作:
- count()->ds.groupBy().count()
- foreach()->ds.writeStream.foreach(…)
- show()->使用命令行输出
操作不被支持时,将会抛出AnalysisException异常。
(3) 流式查询
使用Dataset.writeStream()返回的DataStreamWriter (Scala/Java/Python docs) 启动计算。
需要提供以下参数:
- 输出:数据格式和位置等
- 输出模式
- 查询名称:可选,用于唯一标识
- 触发时间:可选,默认或错过触发时间时,立即执行。
- 检查点存储位置
1) 输出模式
输出模式:
追加
默认。适用于过去数据不再改变的场景。
完全
每次触发输出整个结果表。
更新
只保留当前更新的数据。
不同模式支持不同的查询。
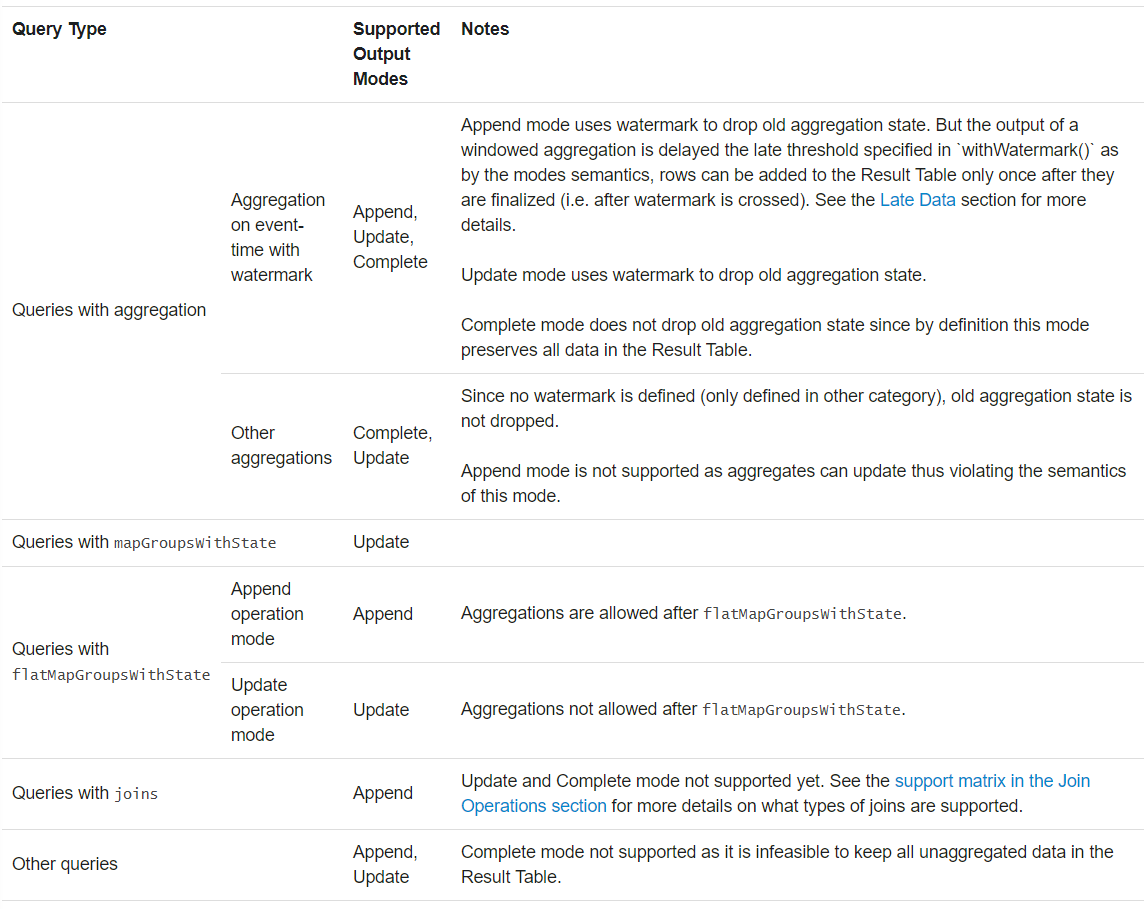
2) 输出Sink
内置输出:
- File sink - Stores the output to a directory.
1 | writeStream |
- Kafka sink - Stores the output to one or more topics in Kafka.
1 | writeStream |
- Foreach sink - Runs arbitrary computation on the records in the output. See later in the section for more details.
1 | writeStream |
- Console sink (for debugging) - Prints the output to the console/stdout every time there is a trigger. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory after every trigger.
1 | writeStream |
- Memory sink (for debugging) - The output is stored in memory as an in-memory table. Both, Append and Complete output modes, are supported. This should be used for debugging purposes on low data volumes as the entire output is collected and stored in the driver’s memory. Hence, use it with caution.
1 | writeStream |

示例:
1 | // ========== DF with no aggregations ========== |
1’ 使用foreach
foreach允许对输出数据执行任意操作。
需要实现ForeachWriter接口,在触发后调用,详见Scala/Java
注意:
- 必须可序列化,因为需要发送到执行器
- open, process和close方法将在执行器调用
- 必须在调用open()后执行初始化操作(如开启连接、开始事务等),否则初始化在驱动节点执行。
- open()方法的两个参数version和partition代表需要输出的记录。version是在每次触发后单调递增的id。partition代表输出的分区,因为分区在执行器间分发。
- open()方法使用version和partition选择输出的记录。true表示输出,false表示忽略
- 除非JVM异常,调用open后会调用close。需要自行清理状态,以避免资源泄漏。
3) 触发
触发用于定义处理的时机。以下为支持的触发类型:

1 | // Default trigger (runs micro-batch as soon as it can) |
(4) 管理查询
StreamingQuery对象管理启动的查询。
1 | val query = df.writeStream.format("console").start() // get the query object |
可以在单个SparkSession中运行任意数量的查询,彼此并行运行并共享集群资源。
使用sparkSession.streams()获取StreamingQueryManager`(Scala/Java/Python docs),用于管理当前活动的查询。
1 | spark.streams.active // get the list of currently active streaming queries |
(5) 监控查询
可以使用以下两种方式监控活动的流式查询:
可以通过以下方法直接获取StreamingQueryProgress对象,包含数据、速率和延迟等:
- streamingQuery.lastProgress()上次触发信息
- streamingQuery.status(). lastProgress()当前触发信息
1 | val query: StreamingQuery = ... |
2) 使用异步API报告
使用sparkSession.streams.attachListener()绑定StreamingQueryListener对象(Scala/Java docs)。可以在查询起止和运行中回调。
1 | val spark: SparkSession = ... |
3) 使用Dropwizard报告
Spark支持Dropwizard Library库,需要先启用spark.sql.streaming.metricsEnabled。
1 | spark.conf.set("spark.sql.streaming.metricsEnabled", "true") |
(6) 检查点恢复
使用检查点和预写日志容灾恢复,可以恢复之前的查询和状态,以及未完成的工作。需要在DataStreamWriter中设置检查点目录:
1 | aggDF |
5 持续处理(试验)
版本>=2.3,Continuous processing是低延迟(约1ms)、至少一次语义和容错保证的流式处理模式。相比之下,默认的微批处理延迟约100ms,保证刚好一次语义。
不需要修改应用逻辑(如DataFrame/Dataset配置),只在查询时改变触发参数,需要提供检查点间隔。
1 | spark |
检查点数据在模式间兼容,每次执行可以选用不同的模式处理。
(1) 支持的查询
版本2.3只支持以下查询:
操作:支持类map操作,即只有投射(select, map, flatMap, mapPartitions, etc.)和选择(where, filter, etc.)
所有SQL函数,除聚(当前不支持)、使用时间的即时计算(current_timestamp()和current_date())
数据源
- Kafka
- 速率:选项只支持numPartitions和rowsPerSecond
数据输出
- Kafka
- Memory
- Console
(2) 注意事项
足够的核心数
持续处理运行多个长时间任务,用于持续读取、处理并输出数据。任务数取决于能够并行得去的分区数量。需要保证至少分区数量个核心可用于查询处理
可忽略的终止警告
终止持续处理可能产生任务终断警告,可以忽略
手动重试
当前没有自动化的失败任务重试,需要手动从检查点重启。
6 附加信息
Further Reading
- See and run the examples.
- Instructions on how to run Spark examples
- Read about integrating with Kafka in the Structured Streaming Kafka Integration Guide
- Read more details about using DataFrames/Datasets in the Spark SQL Programming Guide
- Third-party Blog Posts
Talks
- Spark Summit Europe 2017
- Easy, Scalable, Fault-tolerant Stream Processing with Structured Streaming in Apache Spark - Part 1 slides/video, Part 2 slides/video
- Deep Dive into Stateful Stream Processing in Structured Streaming - slides/video
- Spark Summit 2016
- A Deep Dive into Structured Streaming - slides/video