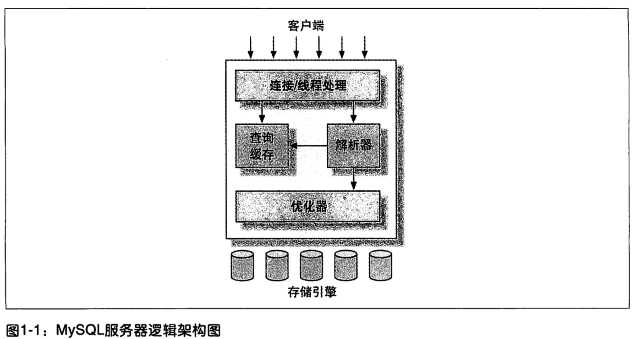
1 逻辑架构
连接/线程处理
类似网络C/S服务,提供连接处理、授权认证和安全等功能
核心服务
MySQL的大部分核心服务
包含下图的查询缓存、解析器和优化器
提供查询解析、分析、优化、内置函数以及跨存储引擎功能(存储过程、触发器和视图等)
存储引擎
负责数据的存取
(1) 连接管理与安全性
每个客户端连接使用一个线程用于查询,服务器缓存线程用以复用。
客户端连接时,服务器负责认证。
(2) 优化与执行
MySQL会解析查询,创建解析树,并优化(包括重写查询、决定表的读取顺序、选择合适索引等)。
2 并发控制
(1) 读写锁
通过两种类型锁组成的锁系统并发控制。
读锁和写锁,也叫共享锁和排他锁。
(2) 锁粒度
在开销和安全间平衡。
表锁
锁定整张表。开销最小
行锁
开销最大,只在存储引擎层实现。
3 事务
一组原子性的SQL查询,要么全部成功,要么全部失败。
(1) ACID
原子性
最小工作单元,不可分割。要么成功,要么失败
一致性
没有中间状态
隔离性
对其他事务不可见
持久性
一旦提交,永久保存
(2) 隔离性
四种隔离级别:
未提交读
没有提交的事务对其他事务可见。
事务可以读取未提交的数据,称为“脏读”
性能上没有明显优势,不推荐
提交读
也叫不可重复读,是除MySQL外大多数数据库的默认隔离级别
事务提交前,对其他事务不可见
同样的查询可能产生不同的结果
可重复读
保证一个事务内多次查询返回相同结果。
MySQL默认隔离级别。
当两个事务分别读写某个范围内数据时,前后两次读可能产生“幻读”问题。
InnoDB和XtraDB采用多版本并发控制MVCC解决幻读问题。
可串行化
强制事务串行执行
导致大量超时和锁竞争问题

(3) 死锁
多个事务相互占用并请求对方的资源,导致恶性循环。
锁的行为和顺序与存储引擎相关。
解决方法:
死锁时返回错误
InnoDB将持有最少行级排他锁的事务回滚
占用超时后释放
(4) 事务日志
修改数据时仅修改其内存拷贝,将修改行为记录到持久化日志中。
效率更高,因为日志是追加的,是顺序写入的。修改后的数据再慢慢写回磁盘。
预写式日志:修改数据需要两次磁盘写操作:事务日志+数据写回。
(5) 事务
MySQL提供两种事务引擎:
- InnoDB
- NDB Cluster
自动提交:默认每个查询都当做一个事务提交。
事务由存储引擎实现。在同一事务混用存储引擎是不可靠的。
同一事务中混用不同存储引擎的表,回滚时,非事务表变更无法撤销,将导致数据不一致。
隐式锁定与显式锁定:
隐式锁定
InnoDB使用两阶段锁定。
事务执行过程中随时能加锁,但锁释放只能在提交或回滚时且是同时释放。
显式锁定
不属于SQL规范
- SELECT … LOCK IN SHARE MODE
- SELECT … FOR UPDATE
此外,服务器层提供LOCK TABLES 和 UNLOCK TABLES锁定。与存储引擎无关,除非事务中禁用了自动提交,否则会导致无法预料的结果且影响性能。
4 多版本并发控制
是行级锁的一个变种,用于避免加锁行为,降低开销。
通过保存数据的快照实现。
大多实现了非阻塞的读和写时只锁定必要的行。
InnoDB实现:在记录后保存两个隐藏的列:创建时系统版本号和删除时系统版本号。
只操作创建<=当前或删除>=当前的记录。更新时,先删除一行,再增加一行。
MVCC只在提交读和可重复读隔离级别工作。因为未提交读只读取最新数据,串行化对所有行加锁,没有必要。
5 存储引擎
MySQL为每个数据库在数据目录下创建一个子目录,为每张表创建一个同名的.frm文件。
不同存储引擎保存数据和索引的方式不同,当表的定义统一在服务层处理。
(1) InnoDB
用于处理大量的短期事务,具有较高的性能和自动崩溃恢复特性。
版本5.1支持排序创建索引、删除或增加索引不需要复制全表、支持压缩存储,支持大型列值和文件格式管理等。
默认隔离级别是可重复读,使用间隙锁避免幻读。
基于聚簇索引建立,对主键查询具有很高的性能。
存储格式是平台独立的。
(2) MyISAM
支持全文索引、压缩和空间函数等,不支持事务和行级锁,崩溃后无法完全恢复。
(3) 引擎选择
除非需要InnoDB不支持的特性,否则使用InnoDB。
除非必需,否则不要混用引擎。
(4) 引擎转换
ALERT TABLE
原表加锁,复制到新表,高效但执行时间长
导出+导入
注意不能同时存在同名表,安全
查询+创建
结合前两者优点,但易人为出错
6 总结
核心基础架构的精髓:存储引擎与服务层交互
参考资料
《高性能MySQL》
两阶段锁定:
优点是高并发,缺点是没有解决死锁问题
- 加锁阶段:只能加锁或处理数据,不能解锁
- 解锁阶段:只能解锁或处理数据,不能加锁
幻读:范围查询时,另一事务向其中插入数据,导致查询结果不一致的现象。
间隙锁:在可重复读隔离级别上,针对非唯一索引,对索引间隙加锁,防止幻读现象。
聚簇索引:表数据按照索引顺序存储,叶子节点存储有行数据。一张表只能有一个聚簇索引。
非聚簇索引:表数据与索引数据无关,叶子节点只存储有指向行数据的指针。一张表可以有多个。