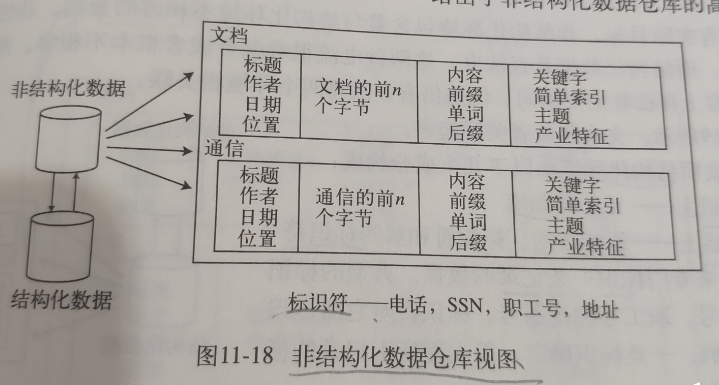
1 非结构化数据
通信
容量和生命周期较短,分布有限
文档
与通信相反
2 结构化与非结构化集成
匹配困难。
两者间的公共连接是文本。
需要考虑以下问题:
- 匹配:是否建立连接
- 上下文:推断关系
- 同名:是否是同一事物
- 别称:同一事物的不同名称
- 缩写
- 不完整
- 词干
匹配前准备:
- 删除无意义的词语
- 将单词简化为词干
- 概率匹配:搜集尽可能多的数据说明两者间的关系。匹配变量越多,有关系的可能性越大。
3 主题匹配
(1) 产业特征主题
先划分主题,在收集匹配信息。根据主题逐一与非结构化数据匹配。
(2) 自然事件主题
先收集匹配信息,再划分主题。
(3) 主题词关联
只要结构化环境中出现了非结构化环境中的关键词就建立匹配。意义不大,其容易误导。
(4) 元数据关联
通过元数据与主题或产业特征主题关联。
4 两层数据仓库
一层非结构化数据,一层结构化数据。
查看非结构化数据需要注意:
- 非结构化数据以低粒度级存在
- 需要一个时间要素
- 数据是按照主题组织起来的
(1) 与结构化层关系
匹配方法:
- 标识符
- 紧密标识符(概率匹配)
- 关键字到元数据或库
匹配依据:
通信
基本标识符,如邮件地址、电话号码等
文档
根据词语和主题
标识符唯一确定一条记录,紧密标识符大概率确定一条记录。
(2) 减少非结构化数据量
- 删除通信废话
- 存储上下文。通常使用关键词前后的语句存储代替整篇文档存储。
- 分开存储通信和文档
- 跟踪使用频率,并选择合适的存储策略
(3) 非结构化数据可视化
与结构化类似,实质是数字的显式。
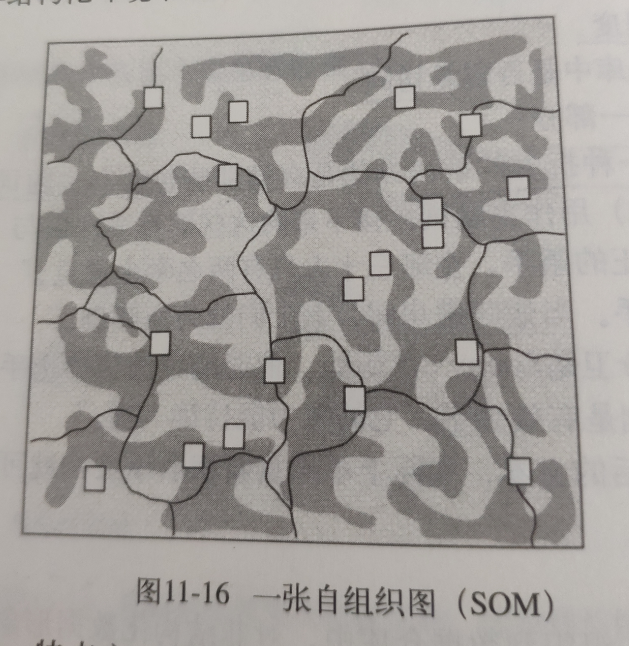
5 自组织图SOM
非结构化数据形象化的结果,显示不同词语和文档聚集方式,并根据主题显示。
特点:
- 展示信息群:非结构化共性和关系
- 具有向下钻取能力
- 提供快速关联文档的能力
参考资料
《数据仓库》