适用于版本2.4.6.
1 概览
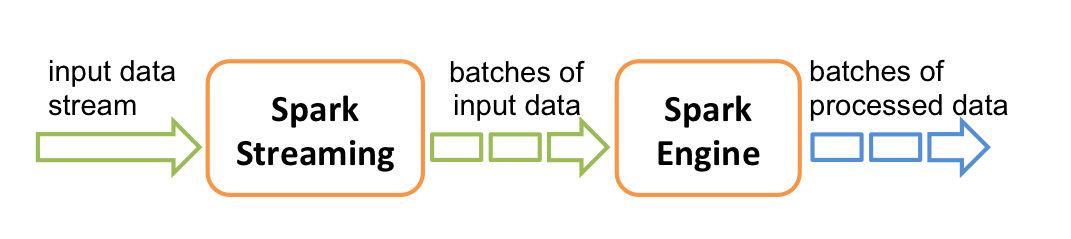
Spark Streaming是核心API的扩展。通过将输入数据流分批处理达到流式处理目的。分批的数据流称为DStream(Discretized Stream, 离散流),内部表现为RDD序列。
支持的输入源有Kafka、Flume和TCP套接字等,支持如map、reduce、join和window等API,可以与MLlib、GraphX等协作。
注意:Python语言API略有不同

2 示例
以下展示从TCP套接字文本数据流中计数单词:
1 | import org.apache.spark._ |
1 | // 使用Netcat作为数据服务器 |
1 | // 在另一个控制台运行示例,结果将每秒输出 |
3 基本概念
(1) 依赖
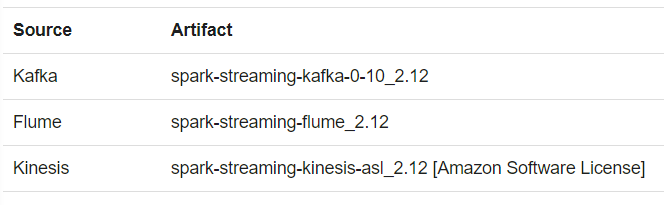
引入合适版本的Spark Streaming库和相应的数据源库,详见Maven repository
1 | <dependency> |
(2) StreamingContext初始化
local[*]参数自动检测CPU核心数,通常用于调试和测试。
SparkContext可以与StreamingContext互相获取。
1 | import org.apache.spark.streaming._ |
注意:
Context一旦启动,不能再添加或修改计算过程。
一旦停止,不能重启。
同一JVM中,只能有一个活动的StreamingContext
ssc.stop()会同时终止SparkContext。除非设置其参数stopSparkContext为false。
SparkContext可以前后有序地创建StreamingContext。
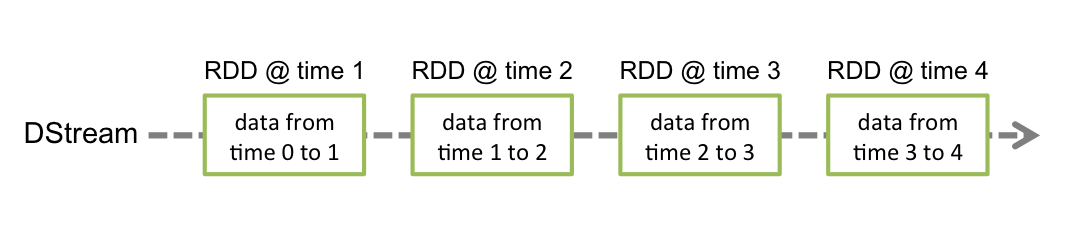
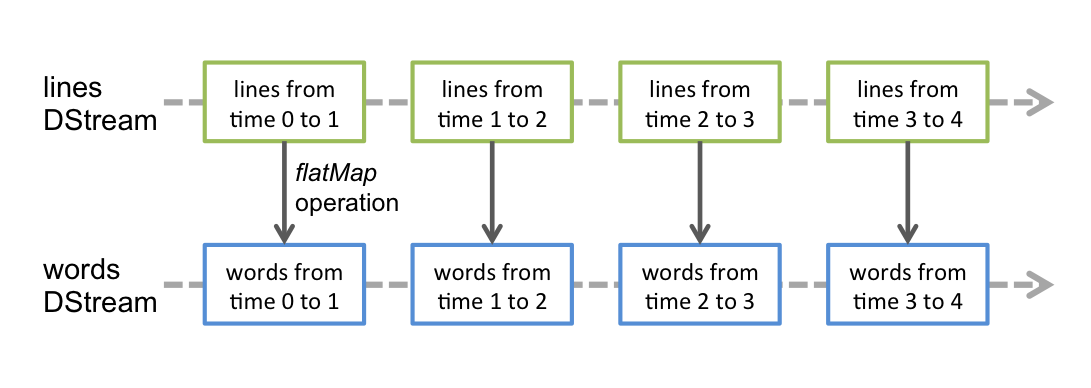
(3) DStream
DStream中的每个RDD代表一个时间间隔的数据。
DStream上的操作会应用到其中的每个RDD上。
(4) 输入与接收
每个输入DStream与一个Receiver (Scala doc, Java doc)对象相关(文件除外)。
Spark Streaming提供两种内置的流式数据源:
基本数据源
即StreamingContext API直接支持的数据源,如文件系统、套接字连接等。
高级数据源
即需要额外库支持的数据源,如Kafka、Flume等。
创建多个DStream可以并行接收数据,详见Performance Tuning。同时需要注意分配给足够的CPU资源。
注意:
运行时,需要分配多于接收器数量的进程,以供数据处理使用。否则不能正常运行。
1) 基本数据源
文件流
文件流不需要接收器,不用分配CPU资源。
1 | streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory) |
文件夹处理
可以使用POSIX glob pattern设置文件夹名称模式,如”hdfs://namenode:8040/logs/2017/*”是2017下所有文件夹,而不是所有文件
目录下的所有文件必须具有相同格式
文件的时间属性是根据修改时间确定的,而不是创建时间。可以通过FileSystem.setTimes()修改。解决办法是文件处理后移动到没有被监控的文件夹中。输出流关闭后立即重命名到目标目录中。详见Hadoop Filesystem Specification。
一旦处理完成,当前窗口将忽略文件的后续更改。
RDD队列
通过streamingContext.queueStream(queueOfRDDs)将RDD队列转换为DStream。
2) 高级数据源
在Shell中使用需要下载相关库并置于类路径下。
3) 自定义数据源
4) 接收器可靠性
可靠接收器
接收器接收,存储并副本后通知数据源。可以避免失效导致的数据丢失。如Kafka和Flume
不可靠接收器
不发送通知的数据源,如选择不发送通知的Kafka和Flume
(5) 转换
详见 For the Scala API, see DStream and PairDStreamFunctions. For the Java API, see JavaDStream and JavaPairDStream. For the Python API, see DStream.
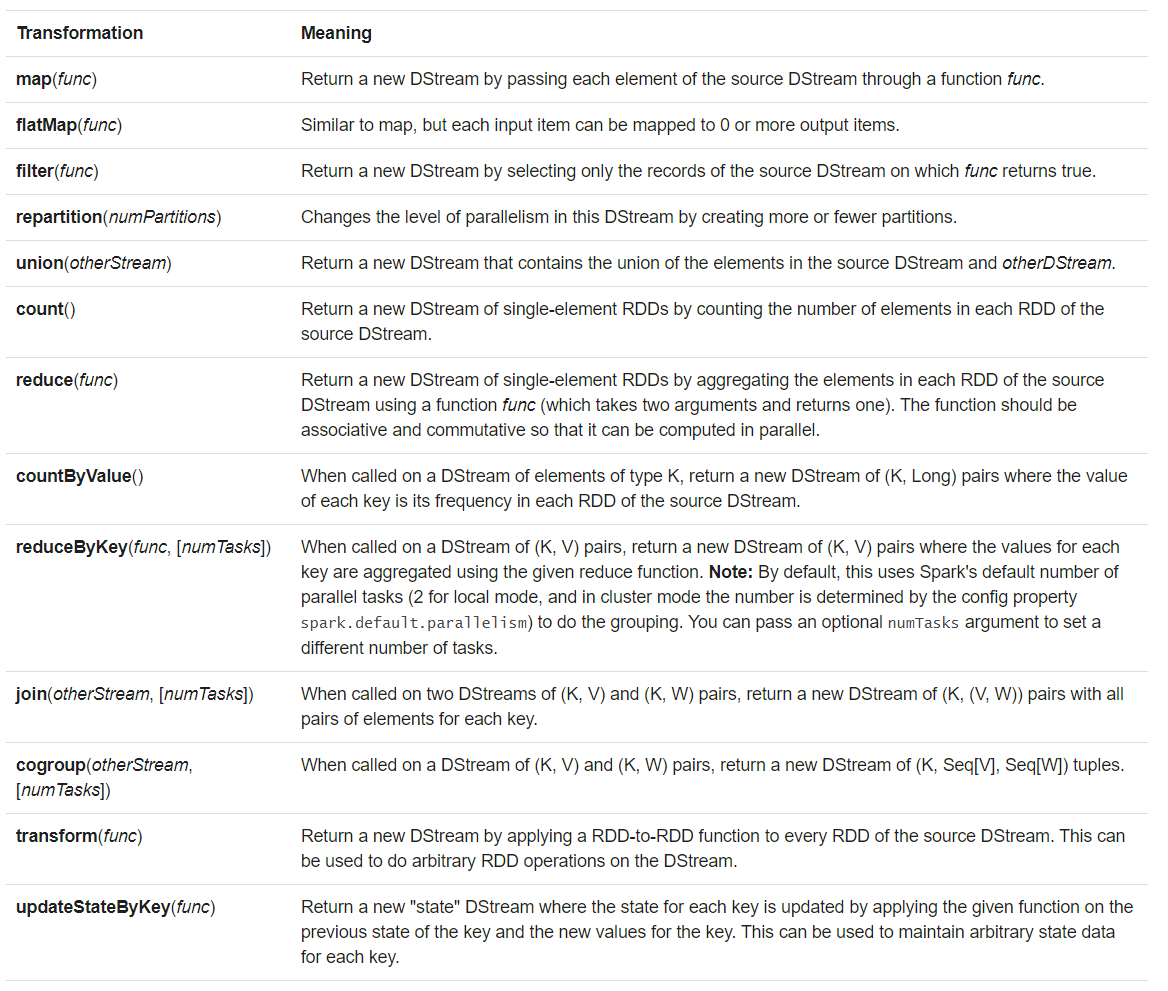
1) UpdateStateByKey
允许持续更新自定义的状态。如单词计数
要求设置检查点目录,详见checkpointing
需要:
- 定义任意类型的状态
- 定义状态更新函数,如根据前一状态和当前数据
1 | def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = { |
2) Transform
允许自定义RDD到RDD的转换。如使用外部数据集过滤元素
应用于每个批处理间隔,因此每个批处理间隔可以具有不同的分区数、广播变量等。
1 | val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information |
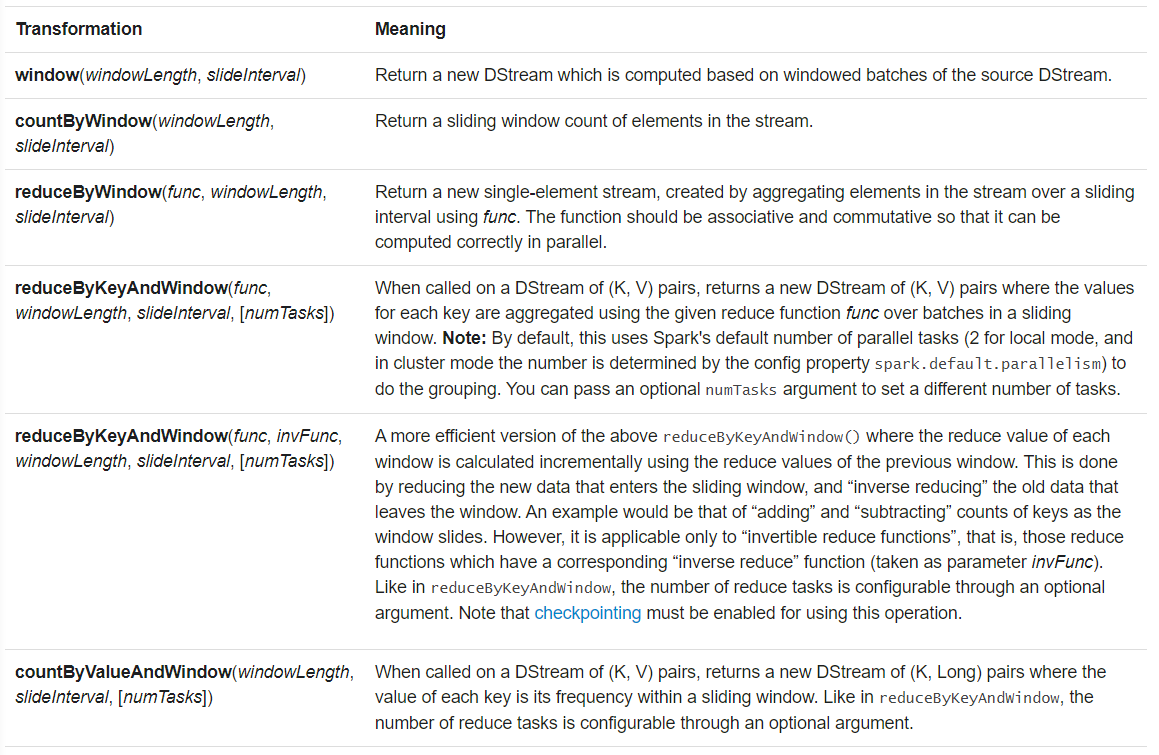
3) 窗口操作
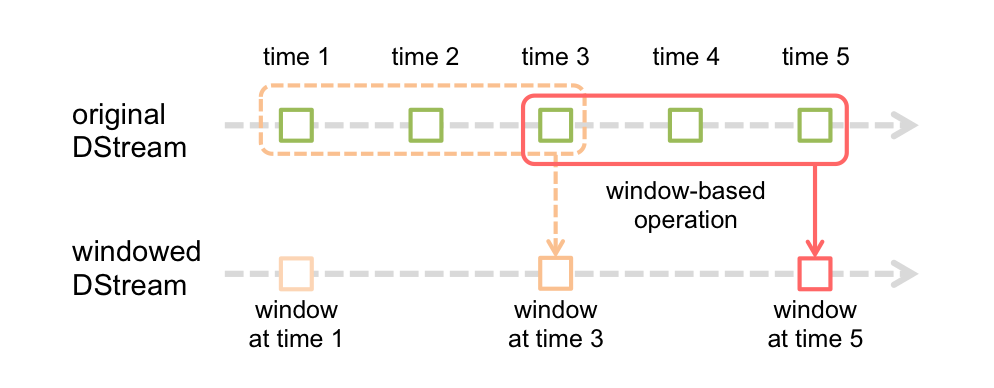
通过两个参数控制:
- 窗口大小:控制每次处理的数据量
- 滑动间隔:控制处理的频率
注意:以上两个参数必须是DStream的倍数。
1 | // Reduce last 30 seconds of data, every 10 seconds |
4) 连接
1’ 数据流与数据流
类似于数据库表连接,有join,leftOuterJoin, rightOuterJoin, fullOuterJoin
1 | val stream1: DStream[String, String] = ... |
2’ 数据流与其他数据集
使用transform和DStream API操作。
1 | val dataset: RDD[String, String] = ... |
(6) 输出

foreachRDD设计模式
对每一个RDD应用函数,并输出到外部文件系统。注意函数执行是在驱动进程中。
1 | // connection会被序列化到工作节点上。由于连接通常不可在机器间传递,会引起序列化和初始化错误。 |
注意:
- DStream是惰性执行的,需要动作触发。
- 默认输出操作按照应用中的顺序依次执行。
(7) DataFrame和SQL
示例详见source code
1 | /** DataFrame operations inside your streaming program */ |
可以异步运行StreamingContext,需要确保其记住了足够的数据,如streamingContext.remember(Minutes(5))
同步运行的StreamingContext当前数据仅在当前查询中有效,过后删除。
(8) MLlib
MLlib提供有一些流式算法, 其余算法可以离线使用。
(9) 缓存与持久化
调用持久化接口可以对整个DStream缓存。
窗口操作自动缓存到内存中。
为了容错,网络输入流默认持久化到2个节点。
与RDD不同,DStream持久化等级是序列化到内存中。
(10) 检查点
用于处理程序逻辑之外的故障。
1) 检查点数据类型
元数据
用于处理驱动节点失效。
数据包含程序配置、DStream操作和未完成的处理
检查点数据保存到容错存储中,如HDFS
数据
用于对状态数据容错。
通过周期性保存中间RDD,避免随着流式程序运行血缘图无限延长
2) 启用时机
通常,简单流式程序不需要启用,除非:
- 需要从驱动节点故障中恢复原先数据
- 包含带状态的操作
3) 配置
通过 streamingContext.checkpoint(checkpointDirectory)提供存储检查点的可靠。容错存储。
此外,驱动程序恢复需要:
首次启动
创建一个新的StreamingContext并配置所有的流,调用start()启动
重启
从检查点目录中重新创建StreamingContext
示例详见RecoverableNetworkWordCount
1 | // Function to create and setup a new StreamingContext |
创建检查点操作耗时,需要平衡计算效率和恢复效率。通常,检查频率设置为5-10个滑动区间。通过dstream.checkpoint(checkpointInterval)配置。
(11) 累加器、广播变量与检查点
累加器和广播变量不能从检查点恢复。
需要创建惰性初始化的单例,以便驱动重启时重新初始化。
1 | object WordBlacklist { |
(12) 应用部署
1) 要求
为窗口缓存数据设置足够的内存
部署框架中配置驱动进程重启,如YARN
write-ahead-logs
版本>=1.2,用于提供容错保证。
接收器接收的所有数据将写入检查点目录的日志中,避免驱动恢复时数据丢失。详见Fault-tolerance Semantics
启用:spark.streaming.receiver.writeAheadLog.enable->true。详见configuration parameter
代价是降低了吞吐量,可以通过多个接收器并行处理弥补。详见more receivers in parallel
使用该功能后,不建议再开启数据副本功能。通过设置StorageLevel.MEMORY_AND_DISK_SER关闭数据副本
对不支持缓冲的文件系统,需要开启spark.streaming.driver.writeAheadLog.closeFileAfterWrite和spark.streaming.receiver.writeAheadLog.closeFileAfterWrite。详见Spark Streaming Configuration
即使设置了加密。Spark也不支持该日志加密。需要文件系统原生支持加密。
最大接收速率
单位:记录/秒
接收器配置:spark.streaming.receiver.maxRate
Kafka配置:spark.streaming.kafka.maxRatePerPartition
Spark自适应:spark.streaming.backpressure.enabled->true。版本>=1.5
2) 代码升级
- 对于可以设置多个接收目的的数据源,新旧程序并行运行,直到新程序可以取代旧程序。
- 对于数据源缓存有历史数据,可以先让旧程序处理完已有数据后终止,再启用新程序接续运行。注意避免检查点信息错乱,需要设置新的检查点目录,或者删除原有信息。
(13) 应用监控
除了monitoring capabilities,还有Spark web UI 可以监控程序运行。
需要注意处理时间和调度延迟。当处理时间超过批处理间隔或者调度延迟持续增加时,需要减少批处理时间。
StreamingListener提供了开发者接口。
4 性能优化
考虑事项:
- 使用集群资源减少批处理时间
- 调整批处理大小,保证数据接收和处理步调一致
(1) 减少批处理时间
详见Tuning Guide.
1) 并行接收
增加输入流消费不同的主题分区,通过增加接收器数量提高吞吐量。合并输入流可以统一转换数据。
1 | val numStreams = 5 |
参数:块间隔spark.streaming.blockInterval
用于在存储到内存前再分区,决定了任务数量。如2s批处理间隔中设置200ms块间隔,将产生10个任务处理。
推荐最小快间隔为50ms,否则导致任务运行过载。
使用inputStream.repartition(\
2) 并行处理
- 设置spark.default.parallelism修改默认的并行数量
- 传递并行等级参数,详见PairDStreamFunctions
3) 序列化
使用Kryo序列化,减少CPU和内部负载
建议注册自定义的类,并关闭对象引用跟踪,详见 Configuration Guide
少量数据或没有窗口操作,关闭序列化,避免GC过载
序列化流式数据类型:
输入数据
默认StorageLevel.MEMORY_AND_DISK_SER_2,序列化+副本,内存不足时溢出到磁盘
默认方案导致接收器需要反序列化接收的数据,并按照Spark的方式序列化
持久化数据
使用StorageLevel.MEMORY_ONLY_SER。
相比RDD,默认增加了序列化,以减少GC负载
4) 任务运行负载
任务数频繁提交将导致明显负载,影响延迟。
- 调整执行模式:优先使用Standalone或粗粒度Mesos,详见Running on Mesos guide 。
(2) 设置合适的批处理间隔
批处理间隔应当与批处理时间一致。
可以通过初始设置间隔为5-10s,观察Spark driver log4j logs中的Total delay或使用StreamingListener接口查看延迟。在数据量稳定时,不断调整间隔以使延迟趋于稳定。
(3) 内存优化
1) 内存分配
当使用窗口函数或状态函数时,分配的内存需要满足存放窗口数据和状态数据的需求。
2) GC
序列化与压缩
使用序列化(如Kryo)和压缩(spark.rdd.compress),用CPU时间换内存容量和GC负载
清除旧数据
Spark自动清理处理窗口外的数据。可以使用streamingContext.remember保存更长时间
垃圾收集器
使用CMS用吞吐量换延迟
使用–driver-java-options或spark.executor.extraJavaOptions配置
堆外存储
持久化RDD为OFF_HEAP等级,详见Spark Programming Guide
更多执行器,更小堆容量
减小每个堆的压力
3) 注意事项
CPU核心数
一个DStream与一个Receiver相关。
并发接收需要创建多个DStream。
每个Receiver占用Executor的一个核。
Receiver以循环模式分配给Executor。
spark.cores.max需要考虑接收和处理各自的核心数量需求。
接收过程
Receiver每个块间隔创建一个块,放入接收的数据。
块数量=批处理间隔/块间隔
当前执行器的块管理器将块分发和其他执行器的块管理器。
随后通知驱动阶段的网络输入跟踪器块的位置信息,以便后续处理。
RDD创建
RDD在驱动节点上创建。
块就是RDD的分区每个分区代表一个任务。
本地执行
map任务在执行器上运行。优先在本地执行。
思考:机架感知?
The map tasks on the blocks are processed in the executors (one that received the block, and another where the block was replicated) that has the blocks irrespective of block interval, unless non-local scheduling kicks in.?
较大的块间隔产生较大的块。
spark.locality.wait值越大,本地执行的概率越大。
需要平衡好块间隔与等待本地执行时间的关系。
其他分区方法
除了块间隔和批处理间隔设置分区数量外,还可以直接指定分区数量。inputDstream.repartition(n)。
代价是对RDD进行shuffle。
合并执行
RDD的处理被驱动节点调度器以作业调度,同一时刻只能有一个活动的,其余排队。
每个DStream将产生一个RDD,每个RDD的处理将产生一个作业。多个RDD将产生串行执行的多个作业。
可以合并DStream以只产生一个RDD,以致一个作业。
注意:RDD的分区数并没有受到影响
暂停接收
当批处理时间超过批处理间隔时,可能导致内存耗尽,抛出BlockNotFoundException。
当前没有方法暂停接收。
可以使用spark.streaming.receiver.maxRate限制接收速率
5 容错语义
(1) 背景
与普通Spark程序不同,Spark Streaming的数据来自网络接收,不容易在故障时重算。因此,会在集群工作节点上保存副本,默认副本数为2。
故障时需要恢复的数据:
- 已备份:从副本恢复
- 未备份:重新接收
需要考虑的故障:
- 工作节点:其上内存中和接收器缓存的数据丢失
- 驱动节点:SparkContext和所有执行器内存中数据丢失
(2) 语义定义
即使发生故障,数据被处理的次数:
- 至多一次
- 至少一次
- 刚好一次
(3) 基本语义
流式系统包含数据接收,数据转换和数据输出三个步骤。
要想实现刚好一次的语义,每个步骤都需要保证刚好一次。
数据接收
需要数据源提供保证。
数据转换
借助RDD特性,只要接收的数据可用,最终RDD的内容不变。
数据输出
默认提供至少一次语义,需要自定义实现刚好一次。
(4) 数据接收
1) 文件
只要输入文件可用,能够从故障中恢复,并实现刚好一次语义。
2) 接收器
根据不同的语义,有不同的容错语义:
可靠接收器
需要接收器通知数据源完成处理,否则还会发送
工作节点失效不会丢失数据
驱动节点失效,丢失所有内存中数据
不可靠接收器
不要通知处理状态
工作节点失效,丢失未备份的数据
驱动节点失效,丢失所有内存中数据
版本>=1.2,提供预写日志write-ahead log,记录接收的数据。可以保证不同故障和接收器下零数据丢失,以及至少一次语义。

3) Kafka
版本>=1.3,新的API保证数据接收刚好一次。
端到端刚好一次,需要自定义输出,保证输出刚好一次。
(5) 数据输出
默认提供至少一次语义。可以通过以下两种方式实现刚好一次语义:
幂等更新
更新同一个文件
事务更新
使用批时间和分区索引唯一标识数据。
使用事务机制输出数据。若已存在,则跳过。
1 | dstream.foreachRDD { (rdd, time) => |
6 学习指引
- Additional guides
- Third-party DStream data sources can be found in Third Party Projects
- API documentation
- Scala docs
- Java docs
- Python docs
- More examples in Scala and Java and Python
- Paper and video describing Spark Streaming.