1 动机
- 大型企业处理所有实时数据的统一平台
- 海量
- 数据加载
- 低延迟消息传递
- 分区、分布式在线处理
- 容错
2 持久化
(1) 文件系统
Kafka高度依赖存储、缓存消息的文件系统。
合适的数据结构可以解决磁盘访问慢的问题。
现代操作系统提供了预读和后写的特性,即预先从多次读取的数据块中提取数据,写入前合并小文件。
顺序读写与随机速写效率相差可达6000倍,甚至磁盘顺序读写快于内存随机速写。详见 ACM Queue article和sequential disk access can in some cases be faster than random memory access
为了补偿预读、后写的性能损失,现代操作系统倾向于将所有的空闲内存用于磁盘缓存。所有的磁盘读写都通过这一缓存。这一特性不同意通过直接I/O以外的方式关闭。
此外,Kafka构建于JVM之上。由于Java对象保存有额外信息,空间占用通常大于实际需求。且垃圾回收负载随着堆内对象的增加而增加。
补充:对于内存存储具有断电易失的特性,通常需要重新加载或计算。
因此,Kafka使用顺序读写的磁盘数据结构,利用操作系统的页缓存,避免额外信息存储、垃圾回收,使用磁盘持久保存的特性。
(2) 数据结构
通常,消息系统使用B树或其他随机访问数据结构。
B树在内存查询中具有对数访问效率,由于磁盘的顺序读写和磁盘查找并发数为1,在磁盘中性能更差。
Kafka根据磁盘顺序读写的特性,采用文件顺序读取和追加的方式,使用偏移能够实现常数复杂度数据访问,并且读写互不干扰。
消费后的数据不是直接删除,而是保留一段时间,有利于消费者的灵活性。
3 效率
目的是解决大量小I/O和字节复制引起的低效。
Kafka协议基于”消息集“的抽象构建。允许合并消息,再发送、追加或获取。
Kafka使用标准化的二进制消息格式,避免数据输出中的操作。
broker维护的消息日志即一个目录下的文件。使用统一的格式,可以使用操作系统命令直接从页缓存发到套接字中,详见sendfile system call
通常,发送文件到套接字,需要经历4次拷贝和2次系统调用:
- 操作系统从磁盘读取文件到内核空间的页缓存中
- 应用程序从页缓存读取数据到用户空间缓冲区中
- 应用程序将用户空间缓冲写入内核空间的套接字缓冲中
- 操作系统复制套接字缓冲到NIC缓冲,随后通过网络发出
而使用sendfile系统调用,只需要1次拷贝,即第4步
使用页缓存和sendfile(零拷贝)可以充分使用网络资源,避免重复从磁盘读取,甚至看不到磁盘活动。
Java支持的sendfile和零拷贝,详见article
端到端批量压缩
在Kafka中实现压缩,可以在压缩的同时,实现批量处理
Kafka支持GZIP、Snappy、LZ4和ZStandard压缩协议
压缩数据在传输和存储过程中保持不变,仅在消费时解压缩。
4 生产者
(1) 负载均衡
生产者直接发送消息到作为对应分区leader的broker中。
所有的节点都可以相应元数据查询请求,以告知发送的位置。
客户端决定消息对应的分区。允许自定义分区函数,如随机算法用于负载均衡、指定分区用于本地化处理。
(2) 异步发送
异步发送允许合并消息批量传输,可以控制合并的窗口大小和批量传输的数据量大小。
详见configuration和 api
5 消费者
消费者每次消费时指定开始的位置,允许消费者控制消费行为。
(1) 推 vs 拉
面向日志的系统,如Scribe和Apache Flume使用推送方式。推送方式可以充分利用消费系统资源。但是数据消费速率由broker控制,难以应对多个消费者。并且容易出现生产大于消费的情形。而拉取模式可以应对供需不平衡的问题。
Kakfa采用推拉结合的方式,数据生产使用推送模式,数据消费采用拉取模式。
消费者使用拉取模式,每次尽可能拉取配置的最大容量,避免了推送模式请求合并引起的延迟。
拉取模式的一个缺点是当broker没有数据时,消费者陷入一个忙循环中。Kafka允许在数据量满足要求前阻塞消费者一段相对长的时间。
对于数据缓存在生产者,全程采用拉取模式的方案。对于具有较多生产者的Kafka应用场景不合适。
(2) 消费位置
跟踪消费位置是消息系统的一个关键性能点。
如果由broker保存,在集群中需要统一维护各节点的消费位置,数据容易不一致。此外,没有确认消费机制容易丢失数据;具有确认机制,容易因消费者而造成多次消费。此外,还需要为每一条消息记录状态。
Kafka通过控制一个分区中的记录只能由消费组中的一个消费者消费,将消费位置信息简化为每个分区的一个整型的偏移值,指示下一消费位置。同时可以自由定义消费的位置。
(3) 离线数据加载
kafka支持批量加载数据到离线系统中。
如Hadoop,为每个分区创建一个任务,然后并行加载。由Hadoop负责任务管理,失败后从原始位置重启。
(4) 静态成员
用于提升流式程序、消费组和基于组内组内平衡协议的应用程序的可用性。
平衡协议通过分配id给成员来协调。这些id是临时的,且会随着成员重启或合并改变。
Kafka允许指定id防止改变引起的责任变化。
配置:
- 版本>=2.3
- 同一消费组内不同消费者设置不同的ConsumerConfig#GROUP_INSTANCE_ID_CONFIG
- 对于Kafka流式应用,每个流设置一个唯一的ConsumerConfig#GROUP_INSTANCE_ID_CONFIG
详见KIP-345
6 消息传递语义
消息传递的“刚好一次“语义保证可以分解为两个问题:发布的可靠性和消费保证。
(1) 发布可靠性
broker为每个生产者分配一个ID,使用生产者ID和消息序列号去重。同时生产者使用类似事务的方式发送消息到多个主题的分区中。
并非所有的用例都需要以上的强保证。对于延迟敏感的场景,生产者可以指定所需的持久性等级,如等待提交的超时、异步、或是仅等待leader收到消息。
(2) 消费保证
消费者位置存储存储在主题中,可以使用上述事务性生产者实现。当下游主题接收到消息时,可以在同一个事务中写入消费者偏移。这与事务的隔离等级有关,在未提交读等级中,未提交事务的消息对于其他消费者可见,而在提交读隔离等级中不可见。
当写入外部系统时,需要协调消费位置和实际输出的位置。可以在消费位置和输出存储间引入“两阶段提交”。但是可以通过将输出和偏移保存到同一位置,实现更简单、通用的方式,避免外部系统对两阶段提交的不兼容。
Kafka默认保证最少一次,通过禁用重试实现最多一次,通过事务性生产者/消费者实现刚好一次。
7 副本
Kafka可以分别对主题设置副本数。
副本的单位是主题分区。副本由一个leader和0或多个follower组成。leader负责分区的所有读写操作,follower负责与leader保持一致的日志。follower像消费者一样获取leader的消息。
Kafka节点存活的条件:
- 通过心跳机制维持与ZooKeeper的会话
- follower紧跟leader消息
Kafka通常使用”in sync”表示节点存活。节点阻塞或落后通过replica.lag.time.max.ms定义。
Kafka不会处理“拜占庭式的失效”,即节点被判定失效后仍旧工作。
更为准确的定义,消息提交成功,即所有的in sync节点记录了该消息。只有提交的消息才会分发给消费者。生产者可以通过acks控制消息提交的标准。
Kafka保证只要有一个副本存活,提交的消息就不会丢失。
(1) 副本日志
Kafka分区即副本化的日志。副本化日志通常是实现state-machine style的基本要素。
副本化日志构建了达成一致性顺序的过程。最简单和高效的方法是,由leader决定值的顺序,follower仅仅拷贝。
follower用于应对leader失效,但需要确保同步了所有提交的消息。同时也产生了一个问题:同步等待时间越长,可能选举出更多的leader。
Quorum:通过确认数量和比较重叠的日志来选举
多数选举:如果一条消息被超过半数的节点确认提交,则确认提交;从超过半数的follower中选择具有最完整日志的作为新的leader。
常见的算法实现:
- ZooKeeper的 Zab,Raft和Viewstamped Replication
- MicroSoft的PacificA,Kafka的实现方式
多数选举的缺点是需要使用数倍的空间,减低吞吐量。通常用于共享集群,为不适合数据存储。
Kafka使用in sync replicas(ISR)记录被leader捕获的follower。只有当消息被所有ISR节点写入后才算提交成功。因此ISR中的节点都可以被选举,并且只有有一个活跃就不会丢失数据。
通过允许客户端决定是否在提交时阻塞,抵消最慢节点同步的代价。并且还提高了吞吐量和磁盘利用率。
Kakfa保证节点在加入ISR前完全同步了消息,因此不需要失效节点恢复数据。
(2) 节点全体失效
如果所有节点失效,从一致性和可用性的角度,有两种leader选举方法:
- 等待ISR中的节点恢复,并选举其为leader(一致性)
- 等待首个恢复的节点,并选举其为leader(可用性)
前者可能永久失效,后者可能丢失提交的消息。
Kafka默认选择一致性,可以通过unclean.leader.election.enable配置。
(3) 可用性和持久性保证
Kafka提供了三种可用性和持久性保证,通过acks参数设置:
- 0:发出即确认
- 1:leader接收即确认
- -1:所有in sync接收才确认
如-1允许in sync中仅有一个节点也可以确认成功。为了提高持久性:
- 关闭unclean leader election。避免数据丢失。
- 设置最小ISR数量。只有不小于数量的节点接收后,才确认。避免但副本失效引起的数据丢失。
(4) 副本管理
副本管理使用循环方式在节点间平衡副本和leader的分布。
Kafka选择一个broker作为controller。负责在broker级别上检测故障,并为失效broker上的所有分区改变leader。因此,可以打包多个leadership更改通知,使选举过程更加快捷。controller失效后会重新选择一个。
8 日志压缩
日志压缩保证Kafka在分区日志中保存有每个Key的至少最近的值,可用于恢复和重启。
日志消息容量和日志过期时间适合临时事件数据,如日志。但是不能应对键值和不可变数据(如数据库表)的变化。
日志压缩允许下游消费者恢复状态,而无需保存所有的更改。
常见的场景:
- 数据库更改订阅:通常在多个系统间维护一个数据集。
- 事件采集
- 高可用日志:通常用于恢复,如Samza
以上场景中,传统的方式需要事实维护更新流,并且需要在故障时加载全部日志。详见this blog post。
保存更新流需要大量的磁盘空间,而丢弃旧更新不能获取当前状态。
日志压缩是基于记录的细粒度保存机制,选择性地移除相同key下的旧更新,保证至少持有key的最新状态。
可以为不同的主题设置不同的保存策略。
该功能受到LinkedIn的数据库变化日志缓存服务Databus启发。
(1) 日志压缩概念
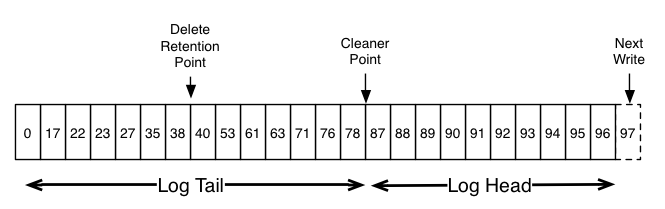
日志分为头尾两部分。头部同传统的Kafka日志,使用连续的偏移保存数据。尾部对具有相同消息状态的偏移去重。
日志压缩允许删除。具有null键值的键名将被删除。删除标记将导致相同键名的旧消息一同被删除。空间释放不是立即执行的,delete retention point指空间释放所到的位置。
日志压缩在后台周期性地复制日志段进行。清理工作不阻塞读取,可以通过配置限制I/O吞吐量。
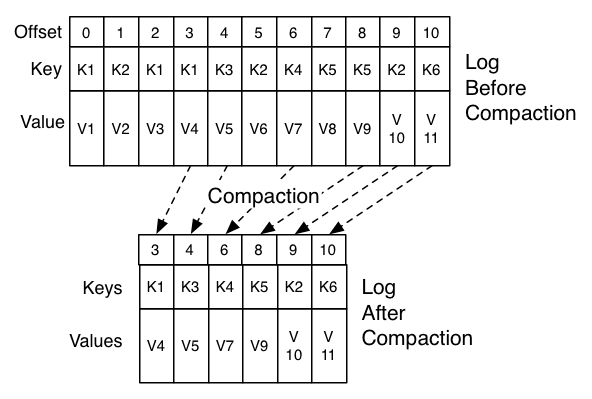
(2) 日志压缩保证
处于头部的数据偏移连续。通过min.compaction.lag.ms和max.compaction.lag.ms控制压缩开始的延迟下界和上界。
日志压缩只删除,不排序
消息偏移不变
消费者至少可以获取delete.retention.ms(默认24h)内消息的最终状态。
Additionally, all delete markers for deleted records will be seen, provided the consumer reaches the head of the log in a time period less than the topic’s
delete.retention.mssetting (the default is 24 hours). In other words: since the removal of delete markers happens concurrently with reads, it is possible for a consumer to miss delete markers if it lags by more thandelete.retention.ms.
(3) 日志压缩细节
日志压缩通过log cleaner实现。log cleaner是用于拷贝日志段、移除记录的线程池。
工作流程如下:
- 选择头尾比最大的日志
- 在头部总结每个key的最新偏移
- 从头到尾拷贝消息并删除旧状态。新的干净段将立即交换到日志中,因此所需的额外磁盘空间只是一个额外的日志段(不是完整的日志副本)。
- 日志总结实际上是一个紧凑的哈希表,使用24字节大小的entry。
(4) 配置Log Cleaner
默认开启log cleaner。
log.cleanup.policy=compact可设置特定主题开启。
log.cleaner.min.compaction.lag.ms或log.cleaner.max.compaction.lag.ms设置清理最早/晚开始的延迟,除了当前偏移。否则只有超过min.cleanable.dirty.ratio才压缩。最晚延迟不是强制性保证。详见here
9 配额
用于控制客户端使用的中介资源。包括:
- 网络带宽配额(字节)
- 请求速率配额,将CPU使用率阈值定义为网络和I/O线程的百分比
(1) 必要性
避免网络饱和和拒绝请求。
(2) 用户组
客户端身份是在安全集群中代表认证用户的用户主体。在不安全集群中,用户主体是由中介通过PrincipalBuilder选择的用户组。客户端ID是客户端选择的逻辑分组。元组(user, client-id)定义了共享用户实体和客户端ID的客户端逻辑分组。
配额可以应用于元组或其中元素。如 (user=”test-user”, client-id=”test-client”) 有10MB/s的生产者配额,因此所有具有相同用户和客户端ID的生产者共享。
(3) 配置
配置可以ZooKeeper目录中实时覆盖,如/config/users 覆盖用户和(用户,客户端ID),/config/clients覆盖客户端ID。
覆盖的优先级如下,从上到下递减:
1 | 1. /config/users/<user>/clients/<client-id> |
(4) 带宽配额
带宽配额定义为共享配额的每个客户端组的字节速率。默认每个用户组以固定配额接收。配额是基于每个broker定义的。在客户端被扼制前,每个客户端组可以发布或获取最大的速率。
(5) 请求速率配额
请求速率配额定义为在配额窗口中,客户端可以使用的中介的I/O和网络线程的时间百分比。资源总量为((num.io.threads + num.network.threads) * 100)%。由于资源是基于CPU的,间接代表了CPU使用率。
(6) 实施
基于每个中介的配置相比全局配置更容易实现,无需在客户端间协调资源。
中介检测的到超额后,首先计算超额客户端恢复 到牌配额下的延迟量并立即返回延迟量给客户端。其次,暂停处理客户端请求至延迟结束。客户端在接收到延迟后,也将在延迟内避免发送请求。因此,双发都能有效地限制配额。
建议使用多个小窗口(如30个1秒的窗口),有利于测量带宽和请求速率,方便快速检测和纠正。而较大的窗口可能导致大量的突发流量和较长的延迟,不利于用户体验。