数据仓库需求只有数据使用后才能逐步了解。数据仓库是在启发方式下建造的。
1 数据加载
从操作型系统加载数据,需要考虑以下几个方面:
集成
- 编码转换
- 度量转换
- 字段转换
- 数据格式转换
效率
- 归档数据:难度不大,且只需一次
- 当前数据:难度不大,且只需一次
- 更新数据:难度较大,可使用5种方式
- 时间戳:方便过滤
- 增量文件:高效
- 日志文件或审计文件:与增量不同的是,受到保护,格式针对系统设计,内容多于所需
- 修改应用代码:不易
- 映像文件:麻烦且复杂,兜底方法
时基变化
规模管理:如数据压缩
2 数据模型
(1) 过程模型与数据模型
过程模型仅适用于操作型环境,而数据模型还能用于数据仓库环境。
过程模型如下:
• 功能分解 • 第零层上下文图表 • 数据流图 • 结构图表 • 状态转换图 • HIPO图 • 伪代码
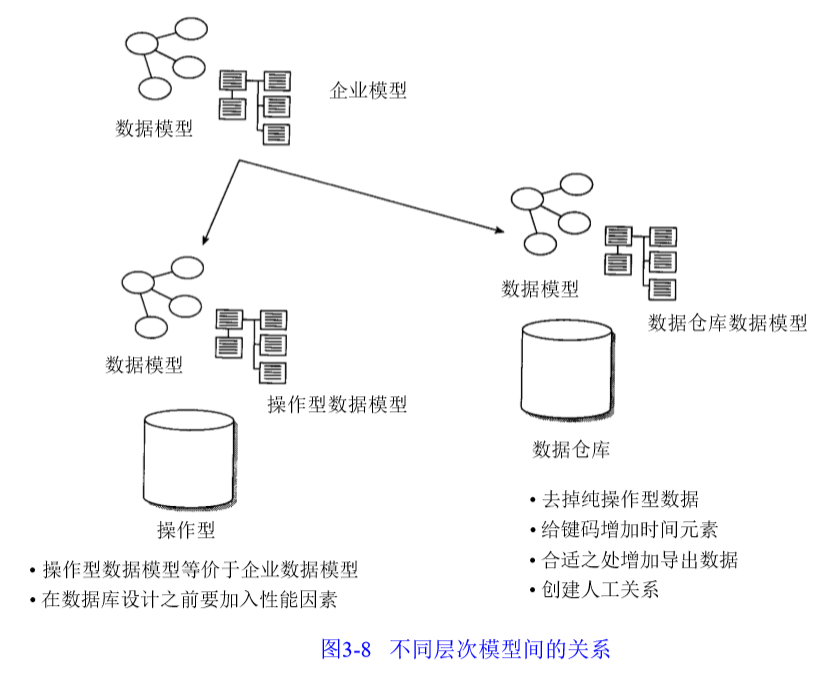
企业数据模型是操作型和数据仓库数据模型的共同起源。
相比于企业数据模型,两者做了如下改动:
操作型
• 等价于企业数据模型
• 在数据库设计之前,要加入性能因素
数据仓库
• 去掉纯操作型数据
• 给键码增加时间元素
• 合适之处增加导出数据
• 创建人工关系
• 稳定性分析:根据各数据属性是否经常变化,将属性分组
(2) 数据模型
数据模型(数据建模)分为三个层次:
- 高层建模(实体-关系图,或ERD)
- 中间层建模(数据项集,或DIS)
- 底层建模(物理模型)
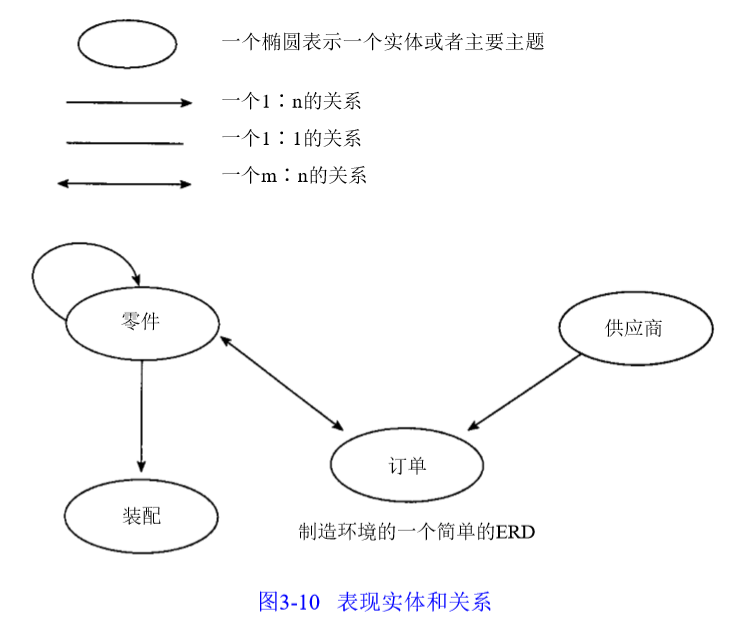
1) 高层模型
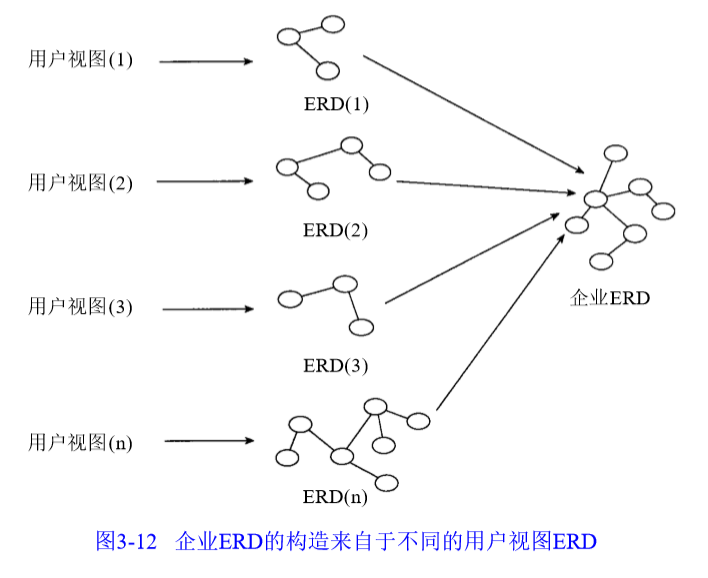
企业ERD是反映整个企业不同人员不同观点的ERD的集成,需要与各部门交流。
集成范围:其内容定义了数据模型的边界,需要在建模前界定。
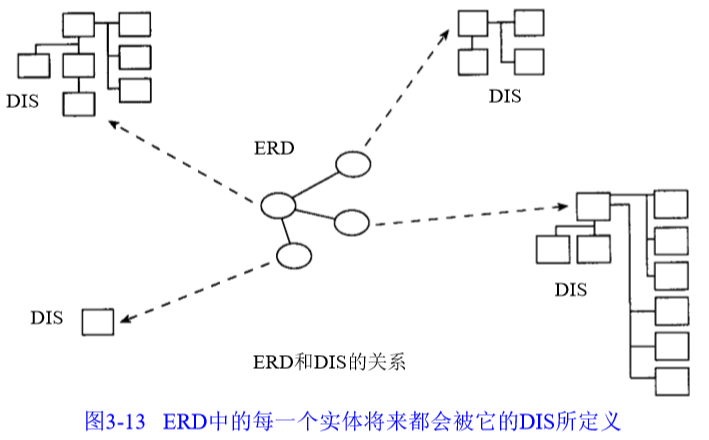
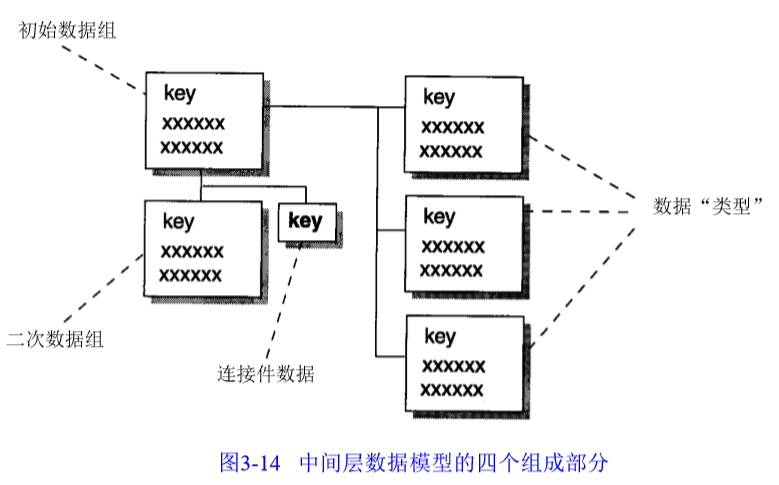
2) 中间层模型
对高层模型中的每个主要主题域或实体,建立一个中间层模型。
数据分组:包含主题域的属性和关键字
中间层模型包含以下4个基本构造:
主要数据分组
包含了每个主要主题域只存在一次的属性。
每个主要主题域有且仅有一个主要数据分组。
二级数据分组
包含主题域存在多次的数据属性
连接器
将高层实体关系反映到中层
数据的“类型”
由指向右侧的线段表示。
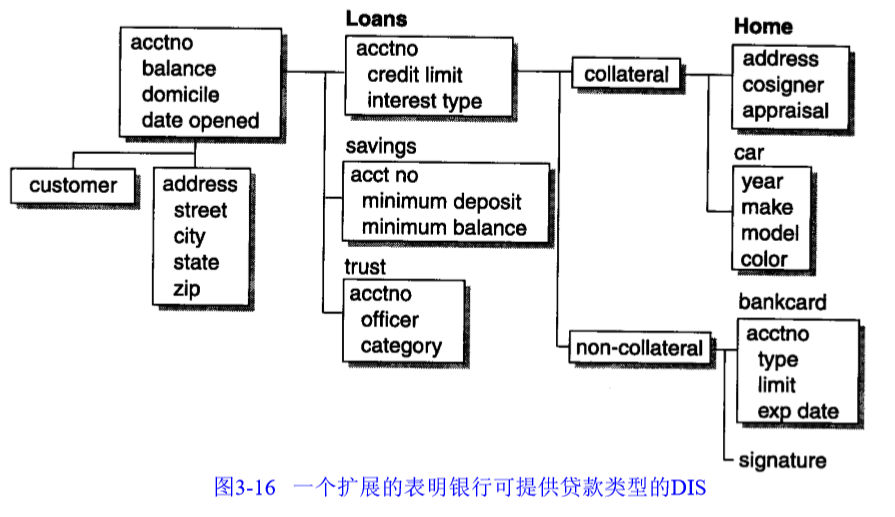
3) 底层模型
扩展中间模型,使模型包含关键字和物理特性。需要考虑性能特性。
表现为一系列表(或称:关系表)。
数据仓库环境中,需要考虑粒度和分区。
物理模型性能设计概要内容如下:
• 数据数组 • 归并表 • 选择冗余 • 进一步分离数据 • 导出数据 • 预格式化,预分配 • 人工关系 • 预连接表
3 迭代开发
用于不断完善需求,需要有可见结果。
基于同一数据模型,迭代结果将是内聚、高度和谐的整体。
4 规范化与反向规范化
目的:减少IO,提高性能
方法如下:
数据数组
通常基于时间索引
要求数组容量稳定、数据顺序访问,并且数据创建和修改有规律
归并表
选择冗余
常用数据在常用处冗余
要求数据稳定
进一步分离数据
按照数据使用频率分解表格
导出数据
提前计算常用的查询,并存入表格待查
人工关系
人为设置的相互关系
参照完整性以人工关系方式出现,表现为数据表之间的动态连接。
创造性索引/创造性概要文件
对可预见的需求,提前进行统计汇总。导出数据?
快照?
5 快照、参照数据
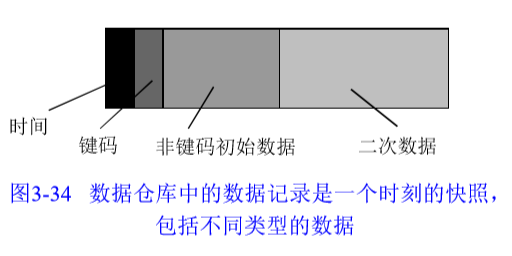
(1) 快照
数据仓库特定事件或时间的数据状态。
数据仓库内部使用快照组织,是数据仓库中最常见的记录方式。
快照触发:
事件
基本组成:
- 关键字:用于标识记录和主要数据,可以不唯一
- 时间单元:事件发生的时刻
- 主要数据:与关键字直接相关的非关键字数据
- 二级数据:外在信息,与主要数据可导出人工关系
时间
(2) 参照数据
操作环境中的表,据此同步数据仓库中的数据?
加入时间元素,反应时变特征
管理方式:
固定时间间隔
每隔固定时间,生成一个快照。
但不具逻辑完备性,期间的波动无法记录
记录变更
记录对参照表的每个活动
但重建数据复杂
6 元数据
与索引类似,位于数据仓库上层,记录数据仓库中对象的位置。
通常,内容如下:
- 数据结构(对程序员和DSS分析员)
- 来源数据
- 数据转换方式
- 数据模型
- 数据模型与数据仓库关系
- 数据抽取的历史记录
7 数据周期
从操作型环境中数据发生改变,到数据仓库环境中反映出来的时间间隔。
需要平衡好与同步耗费、波动细节间的关系。
8 转换与集成复杂性
(1) 问题
- 数据抽取,在不同DBMS、操作系统、硬件和数据结构间
- 数据选择,过滤出所需数据
- 关键字重建或转换,加入时间成分,重新散列或重建
- 格式化
- 数据清理,如范围检查、交叉记录检验和格式检验等
- 多源数据合并
- 排序
- 综合
- 提供默认值
- 效率
- 重命名
- 定长与边长记录
- 不定
- 字句
- 数据关系
- 海量数据
(2) 自动化工具
ETL
需要转换和格式化。分为以下两种:
生成源码
可以原始数据格式访问
生成参数化模块
需要提前统一数据格式
ELT
优点:转换时可以引用大量数据
缺点:试图跳过转换,降低了数据仓库价值
9 记录触发
导致数据加载的基本业务交互活动,称为“事件-快照”交互。
(1) 事件
- 业务活动:随机
- 时间:有规律的
(2) 组成
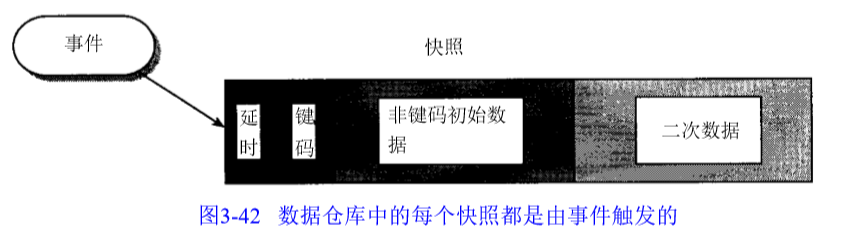
- 时间单元:一般标记快照产生时间
- 关键字:标记快照
- 主要非关键字数据:与关键字相关的数据
- 二级数据(可选):关系的人工因素
10 概要记录
以聚集的形式代表多条操作型记录。
场景:
- 数据不稳定
- 数据量大
- 不要求十分详细
聚集形式:
- 汇总
- 计数
- 统计
- 首尾表示
- 新旧表示
- 分区取值
- 分时取值
实践方案:
- 迭代建立,适时修改
- 及时归档,保证完整
- 通常在操作型环境完成,因为需要排序和合并
11 从操作型访问数据仓库
可行,但有限制
(1) 直接访问
限制:
- 非在线,能够忍受较长的响应时间
- 少量数据返回,通常KB级别
- 技术一致,如协议等
- 基本不做格式化
(2) 间接访问
预先离线计算,再在线查询结果
考虑因素:
分析程序
人工智能、平台无关、后台运行、与变化步调一致
周期刷新
低频率
在线获取
每个数据单元仅含少量数据。
数据单元可大量。
批量、周期刷新
访问效率高
12 星型连接
数据规范化优点:
- 灵活
- 适合粒度化数据
- 与数据模型匹配
多维方法:一种数据仓库设计方法,需要星型连接、事实表和维度。只适合于数据集市,不适合数据仓库,因为数据仓库无法做到对每个部门最优,需要牺牲其他部门的利益。
星型连接:用于管理数据集市中大量加载的实体数据的设计结构。有中央的,大量载入实体的事实表和周边实体的维度表构成。事实表通过任意多个外键与维度表连接。
优点:优化数据,通过预连接数据和选择性数据冗余,提高数据访问和分析的效率。
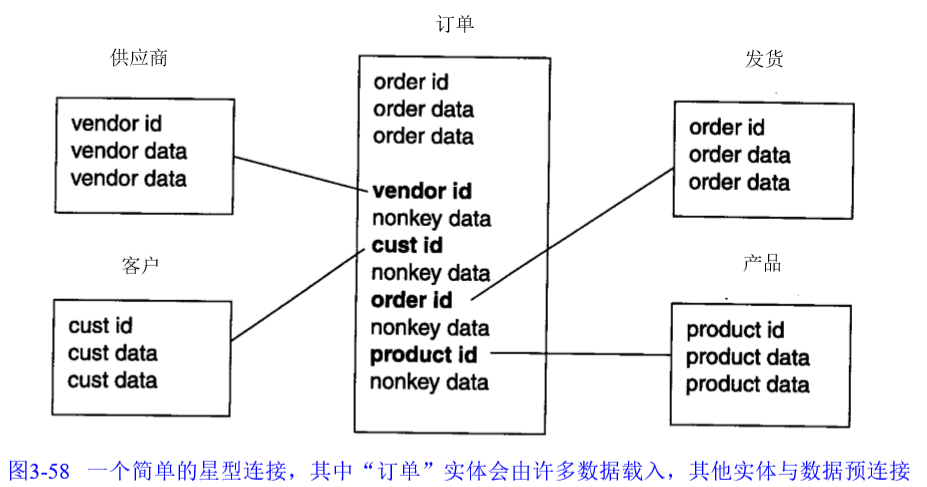
数据集市与数据仓库区别:主要在数据结构上。数据集市中的数据结构,定制化程度高,与其他部门兼容性低。
13 操作型数据存储
分为4类:
- 同步
- 短时
- 夜间
- 不定期
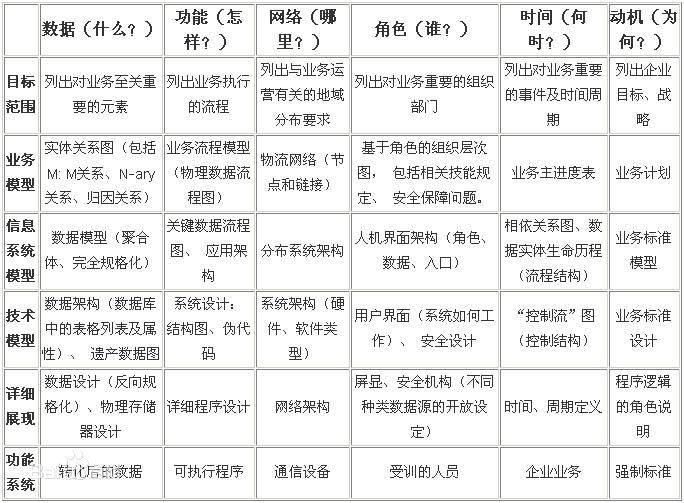
14 Zachman需求框架
用于聚集和组织企业需求。获取企业视图,促进数据仓库设计和开发。
参考资料
《数据仓库》