数据仓库是体系结构化环境的核心,是决策支持系统处理的基础。
数据仓库应该进行一致性编码。
数据加载时是以静态快照的格式进行。
数据仓库中数据与当前值不同。
(1) 结构
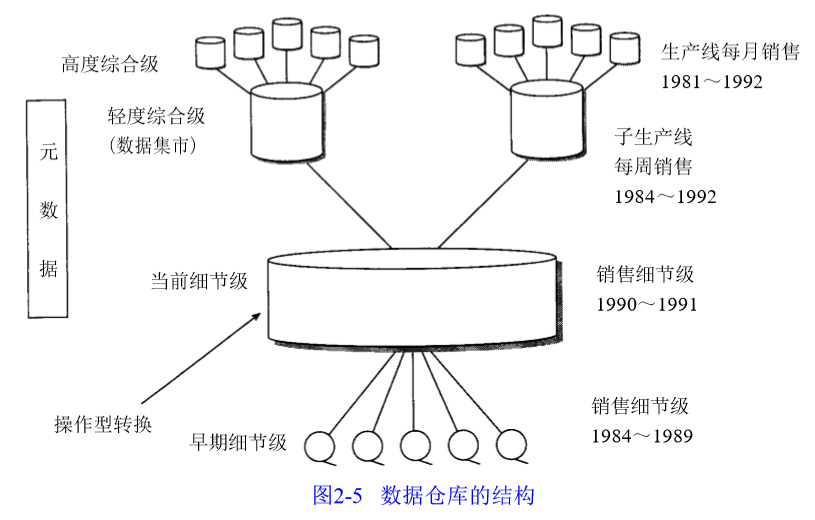
数据存在着不同的细节级:
早期细节级
数据过期后,由当前细节级转入。通常存储在备用海量存储器上。
当前细节级
导入数据
轻度综合数据级(数据集市级)
高度综合数据级
(2) 面向主题
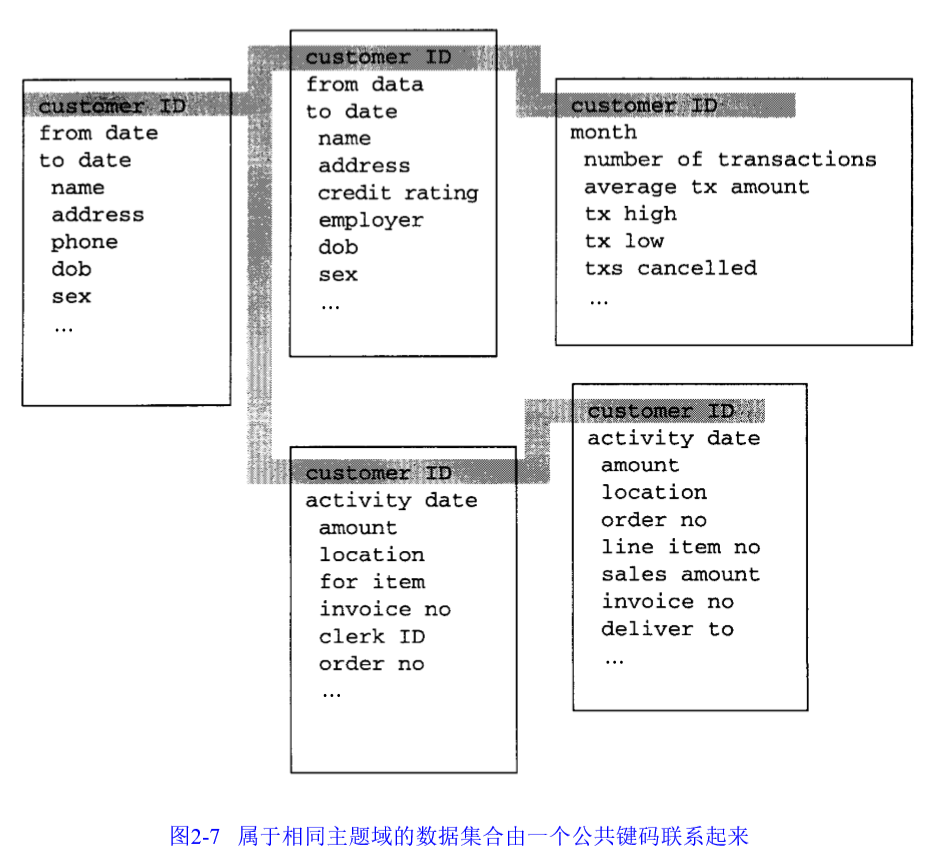
数据仓库面向高层企业数据模型中已定义好的企业主题域。
每个主题域由多个相互关联的物理表组成。
主题域中,所有物理表通过一个公共关键字联系。
每条记录都有一个时间元素。其中以起止时间为基础组织的,称为数据的连续组织。

(3) 逐步构建
数据仓库是有序逐步构建的。
- 熟悉操作型事务处理系统
- 第一个主题域加载最初的表数据
- 更多的数据加载到数据仓库
- 数据集市兴起
- 多维系统出现
- 体系结构充分发展
(4) 粒度
粒度是设计数据仓库的最重要方面。
粒度指数据单元的的细节程度或综合程度,影响数据量和数据仓库应答能力。
1) 优势
- 观察数据的不同角度。
- 细粒度带来改变观察角度的灵活性,可以自由综合。
- 包含企业活动和事件的历史。
- 应对未知需求的能力。
2) 劣势
细粒度数据量大,查询检索过程耗费大
粗粒度综合程度高,细节丢失多
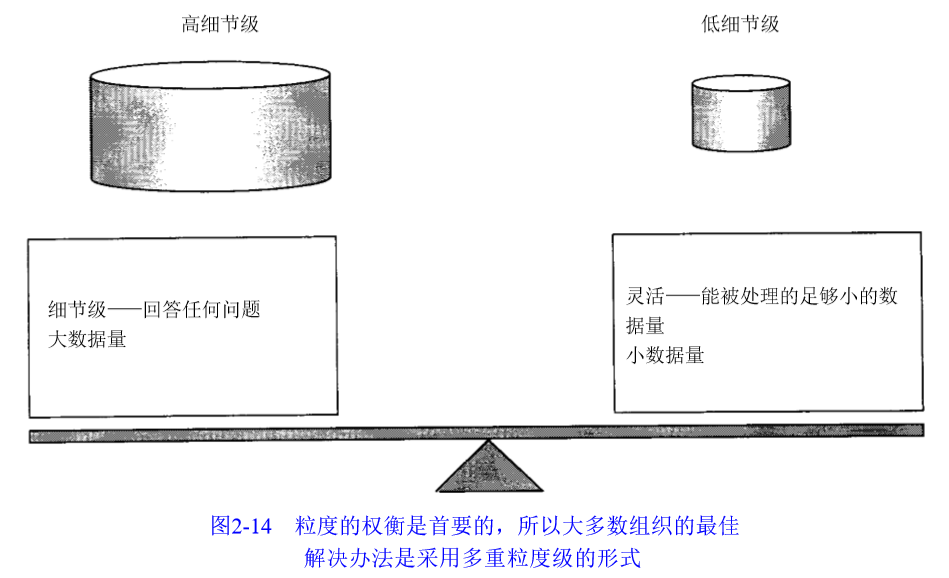
3) 双重粒度
适用于数据量大时,基于费用、效率、易用和应答能力的最佳选择。
包含两种类型数据:轻度综合数据和“真实档案”数据
轻度综合数据应对大部分处理,“真实档案”数据应对更大细节级分析处理。
(5) 活样本数据库
是周期刷新的数据仓库的数据子集。
不是通用的数据库,适用于统计分析和趋势观察,不适用于处理单条数据。
使用选择函数(通常为随机)抽取数据仓库样本。
优点是存取次效率高。
可用于DSS分析员需求理解时的迭代处理。
(6) 分区
分区是数据仓库设计中的第二个主要问题。
目的是将数据划分为小的可管理的物理单元,以应对数据增长和管理。
一个数据单元属于且仅属于一个分区。
常见分区标准:
- 时间
- 业务范围
- 地理位置
- 组织单位
- 以上所有
分区方式:
系统层
依赖于DBMS和操作系统,不知道分区间的关系,通常只有一种数据定义
应用层
由开发者控制,可以有不同的数据定义
(7) 数据组织
简单堆积
以逐个记录为基础堆积数据,最简单和常用。细节丰富,但数据量大
轮转综合
周期地按层次综合数据。相对紧凑,但有细节丢失。时间越久,细节丢失越多。
简单直接
操作型数据间隔一定时间的快照。可以是时间窗口内简单直接文件的综合,也可以是当前快照与最近连续文件的追加。
(8) 审计
不应该在数据仓库中进行审计。
主要原因:出现之前没有的数据、改变时间标定过程、改变备份和恢复机制、限制粒度为最细
(9) 异构
数据仓库中的数据是异构的。主题域间不同,域内表间不同。
(10) 数据清理
- 轮转综合
- 移动到备份大容量存储中
- 删除
- 体系结构层次转移,如从操作层到数据仓库层
(11) 报表
操作型系统和数据仓库都可以报表处理,但是面向对象和用户不同。
操作型报表
主要是行式项目,供基层人员使用
数据仓库报表
主要是综合或其他计算,供管理层使用
(12) 数据纠错
更改先前错误数据
优点
干净、彻底
缺点
1 破坏集成性。利用错误数据生成的报表失去一致性
2 在数据仓库环境中更新。
3 需要修正的条目众多。由于其他数据对该数据的依赖?
额外加入修正条目
优点
反应最新数据状态
缺点
1 需要修正的条目众多。
2 可能修正公式复杂。
重置当前数据
优点
不用考虑之前的数据
缺点
1 需要与应用、过程约定
2 缺乏对错误数据的解释。错误数据在哪?
参考资料
《数据仓库》
近线存储:磁带,自动控制的基于卡式磁带机的串行磁带。
操作型窗口:操作型环境中档案数据的时间范围。