1 定义
分布式流式平台。
(1) 三大能力
- 发布、订阅流式记录,类似消息队列和企业消息系统。
- 容错且持久地保存流式记录。
- 即时处理流式记录。
(2) 两大用途
- 构建可靠的实时流式数据管道
- 构建实时流式数据转换/响应应用
(3) 概念
- 运行在可扩展的集群上
- 分类(主题)保存流式记录
- 每条记录包括键名、键值和时间戳
(4) 五个核心API
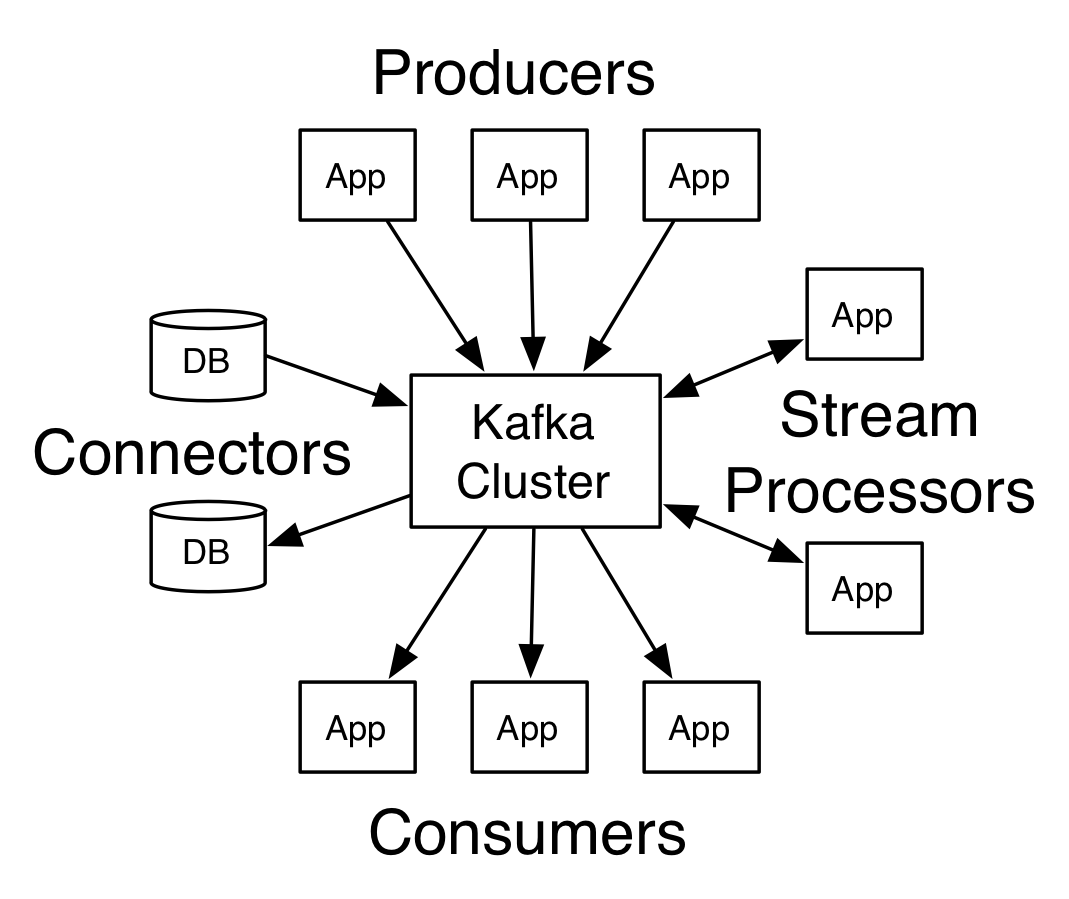
- Producer API
- Consumer API
- Streams API
- Connector API
- Admin API:用于管理和查看Kafka
2 主题和日志
主题是Kafka对记录流的核心抽象,是记录发布的目录或者反馈。
一个主题可以有0或多个订阅者。
对于每一个主题,kafka集群维护如下的分区日志:
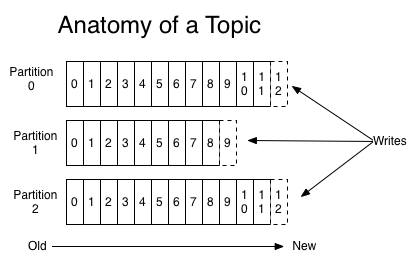
每个分区是一个有序的、不可变的记录序列。记录持续追加到序列后。分区为每条记录分配一个唯一的id,叫offset。
无论是否被消费,kafka始终持久化发布的记录。可以使用可配置的保留时间,以删除超时的数据。Kafka性能与数据大小无关,因此可以长时间存储数据。
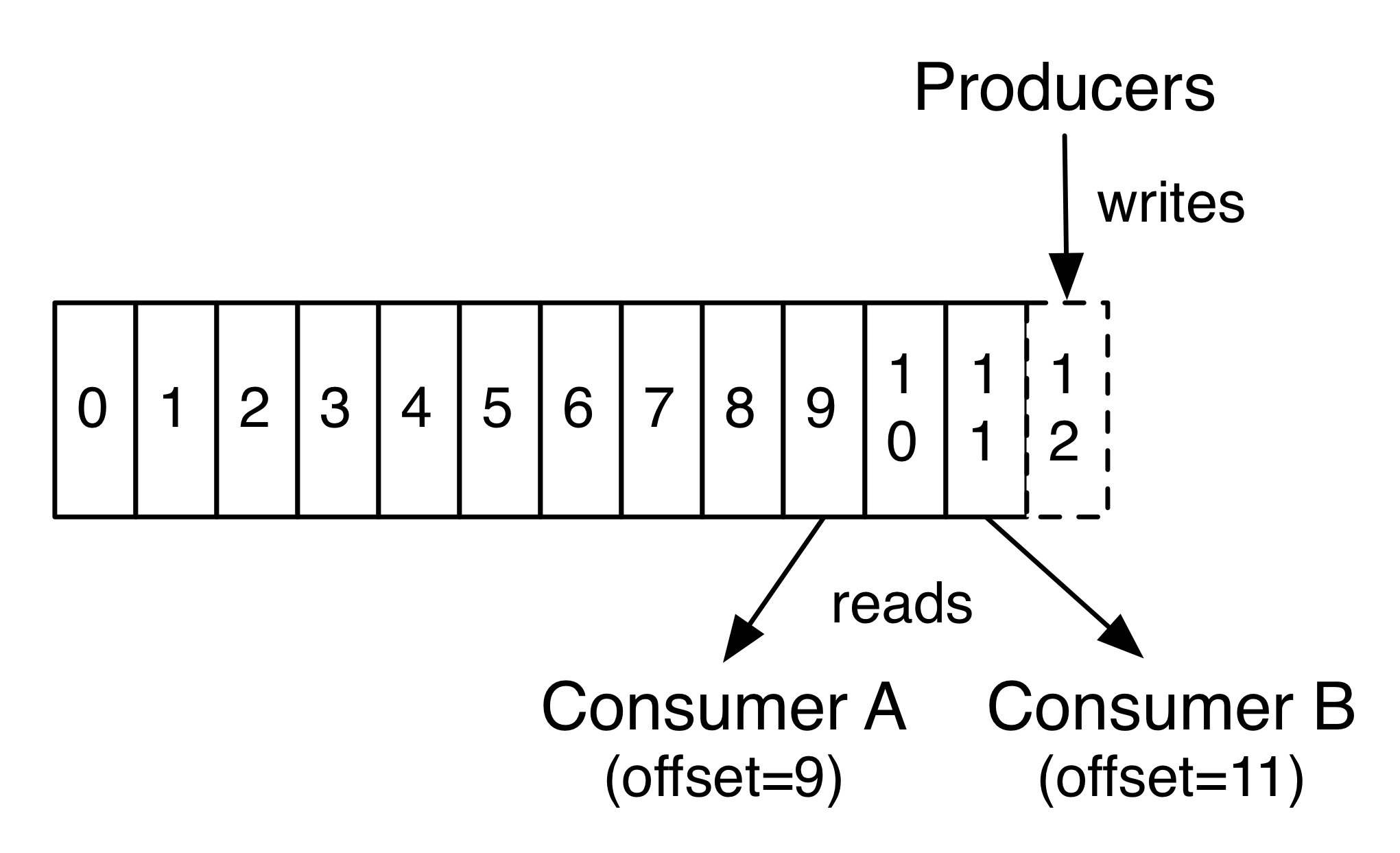
事实上,消费者保留的元数据只有offset。通常按照顺序逐一访问,但消费者可以自主决定访问的顺序等策略。
由于不影响主题中的数据,消费者间互不影响。
日志分区有以下作用:
(1) 避免单台服务器磁盘容量限制
(2) 作为并行的单位
3 分布
分区在集群节点间分布,同时分区又在节点间重复。
对于单个分区,有一个节点作为leader,其他作为follower;对于单个节点,可能是一些分区的leader,一些分区的follower。leader负责分区读写,follower被动复制分区。当一个分区的leader故障后,会有一个follower自动称为leader。这种机制保证了集群内的负载均衡和容错。
4 地理副本
Kafka MirrorMaker提供集群的地理副本功能。消息在多个数据中心或云区域间复制。可以使用主动/被动场景用于备份和恢复,或使用主动/主动场景用于将数据靠近用户,或支持数据本地化需求。
5 Producer
Producer负责按照某种分区函数将数据发布到分区中,可以是循环(有利于负载均衡)或其他某种。
6 Consumer
Consumer可以划分为Consumer Group。每个Consumer Group可以包含若干个Consumer。Consumer可以在不同的进程或机器上运行。
如果所有的Consumer在同一个Group中,记录将在Consumer间高效负载均衡。
如果所有的Consumer在不同的Group中,消息将广播给所有的Group。
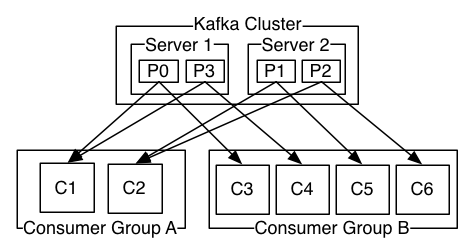
思考:单条消息每个Group发一次,Group内Consumer间消息负载均衡?
Group中加入新实例,将分摊组内其他实例的分区;实例故障,将把自身的分区分摊给其他实例。
Kafka只提供单个分区的顺序,不保证同一topic中分区间的顺序。可以设置主题只有一个分区来实现。尽管这意味着一个Group只有一个Consumer实例。
思考:如果是多个实例,一个分区中的特定消息只会发给Group中的一个实例,其他实例接收不到,并且实例间难以知晓顺序。
7 多租期
可以将kafka用于多租期解决方案,通过配置能够生产或消费数据的主题。
支持配额操作。管理员可以定义和加强请求的配额,以控制broker资源。
8 保障
- 同一生产者生产的消息,在同一分区中按照发送的先后追加。
- 消费者所见的消息按照日志中的顺序排列。
- 在不丢失记录的前提下,具有N个分区的主题允许有N-1台服务器失效。
9 消息系统
消息系统通常有两种模型:队列和发布/订阅。
(1) 队列
多个消费者从服务器读取,每条消息只到达其中一个消费者。
优点:允许在多个消费者之间划分数据处理任务
缺点:不能有多个订阅者。一旦消息被读取就消失了。
(2) 发布/订阅
消息被广播给所有消费者。
优点:允许广播给多个订阅者
缺点:不能划分数据处理任务
(3) 消费组
Kafka使用消费组结合以上两种概念。
Kafka允许在组内多个消费者间划分处理任务。
Kafka允许在消费组间广播消息。
(4) 顺序保证
传统队列模式中,虽然按序分发消息,但是由于网络异步,无法保证到达多个消费者的先后顺序。通常限制只有为只有一个消费者,但是处理不再是并行的。
kafka可以同时实现顺序保证和负载均衡。每个主题的一个分区只能被一个消费组中的一个消费者消费。
10 存储系统
与消费解耦的,允许发布消息的任何消息队列可以视为一种空中消息的存储系统。
写入Kafka的数据被存储并副本到磁盘。Kafka允许生产等待消息被确保副本并持久化后的通知。
Kafka使用的磁盘结构可以应对不同的数据量。
Kafka保存并允许客户端控制读取位置,因此可以被视为一种特殊用途的分布式文件系统。其致力于高性能、低延迟提交日志存储、副本、传播。
详见Kafka’s commit log storage and replication design
11 流式处理
Kakfa通过Streams API提供记录流处理功能。其构建在Kafka核心概念之上,使用Producer和Consumer用于输入,使用Kafka用于状态存储,使用此昂通的组机制用于在不同实例间容错。
12 结合消息、存储和流式处理
存储功能可以管理历史数据,消息功能可以管理未来数据,流式处理可以处理数据。三者结合可以处理过去与未来产生的数据。