1 概览
Spark具有两大抽象: RDD和共享变量。
RDD是节点间分区并行操作的元素集合。可以通过Hadoop支持的文件系统中的文件或者已有的RDD转换得到。可以持久化,也可以容灾恢复。
共享变量是并行任务间共享的数据。分为广播变量和累加器。
2 连接Spark
Spark 2.4.5默认使用Scala 2.12,可以自行编译其他版本。
Maven依赖:
1 | // Spark |
导入类:
1 | import org.apache.spark.SparkContext |
3 初始化Spark
(1) 应用程序
SparkConf用于提供应用信息,每个JVM只能有一个。
SparkContext用于访问集群
1 | // appName 集群UI显示的应用名称 |
master:
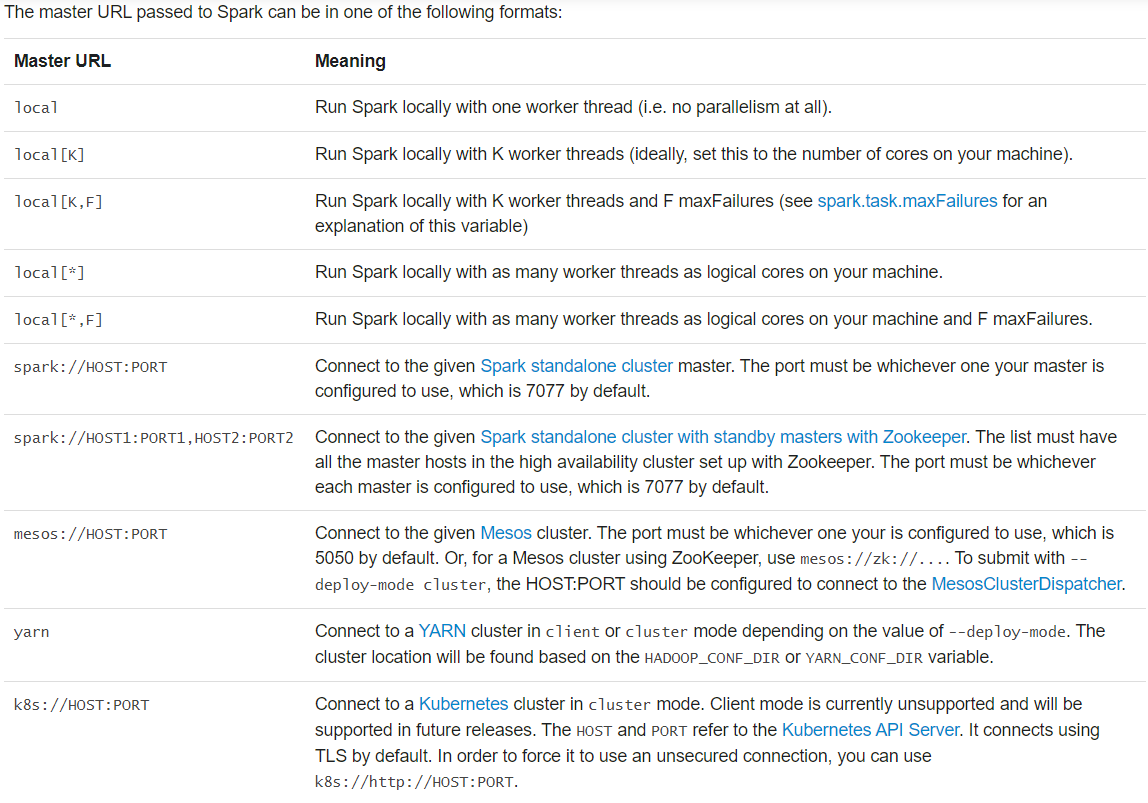
如果不想硬编码master,可以使用spark-submit
(2) 交互命令行
spark-shell自动创建SparkContext,忽略用户创建的。
1 | // --master 指定连接的主节点 |
4 RDD
(1) 创建
RDD有两种生成方式:并行化驱动程序中的集合,从Hadoop支持的外部数据源导入
1) 并行化集合
使用SparkContext.parallelize()并行化驱动程序上的已有数据集合。
可以指定数据分区(partition或slice)数量。计算时,Spark为每一个分区分配一个任务。Spark默认基于集群分配。也可以在参数中显式分配。通常为每个CPU分配2-4个分区。
1 | val data = Array(1, 2, 3, 4, 5) |
2) 外部数据集
支持所有Hadoop InputFormat,可以在参数中指定分区数量。对于HDFS默认按照块(默认128MB)数量分区。
本地文件:使用本地路径时,需要所有worker具有相同路径的文件
文本文件:SparkContext.wholeTextFiles可以按照目录读入文本文件,返回(filename, content)键值对。
SequenceFile:使用SparkContext.sequenceFile[K, V]读入。K和V是Hadoop中Writable 接口的子类。对于原生类型,自动转换为对应类。如sequenceFile[Int, String] - > sequenceFile[IntWritables, Text]。
其他格式的Hadoop文件:使用SparkContext.hadoopRDD或新的接口SparkContext.newAPIHadoopRDD。
RDD.saveAsObjectFile和SparkContext.objectFile支持以序列化Java对象的格式保存RDD,但是没有Avro高效。
(2) 操作
RDD支持两种操作:转换和动作。
转换将RDD从已有数据集转换到新的数据集。动作通过计算数据集,返回值给驱动程序。
所有的转换都是惰性的。为了提高效率,只有当动作使用相应的数据时才计算。
为了避免重复计算,可以使用persist或cache中间转换结果RDD。
1) 基础
示例
1 | // 读入也是惰性的 |
2) 函数传递
Spark十分依赖于在驱动程序中函数传递以在集群上运行。推荐使用以下两种方式:
- 匿名函数
- 全局单例对象的静态方法,如下:
1 | object MyFunctions { |
可以传递一个类实例的方法引用的方式实现:
1 | // map中引用对象方法func1,需要将整个MyClass对象发送到集群中 |
3) 闭包
集群执行代码时,理解变量的作用域和生命周期是个难点。
以下以foreach()中增加计数器为例:
1 | // 反例 |
1’ 本地vs集群
闭包是在执行器计算时必须可见的变量和方法。闭包被序列化并发送给每一个执行器。
当闭包内使用外部对象时,使用的是副本,对于原来的数据没有影响。
虽然在本地同一JVM下执行可能正确,但是不推荐。
建议使用累加器。
2‘ 打印RDD元素
集群模式时,标准输出是在执行器本地。
- 使用collect(),将整个RDD返回到驱动节点。但可能耗尽驱动节点内存。
- 使用take()获取指定量的元素到驱动节点
4) 键值对
Scala中,使用Tuple2实现,键值对操作在类 PairRDDFunctions中。
注意:使用自定义对象,需要实现hashcode()和equals()。详见Object.hashCode() documentation.
5) 转换
详见RDD API doc (Scala, Java, Python, R)和pair RDD functions doc (Scala, Java)

6) 动作
详见RDD API doc (Scala, Java, Python, R)和pair RDD functions doc (Scala, Java)
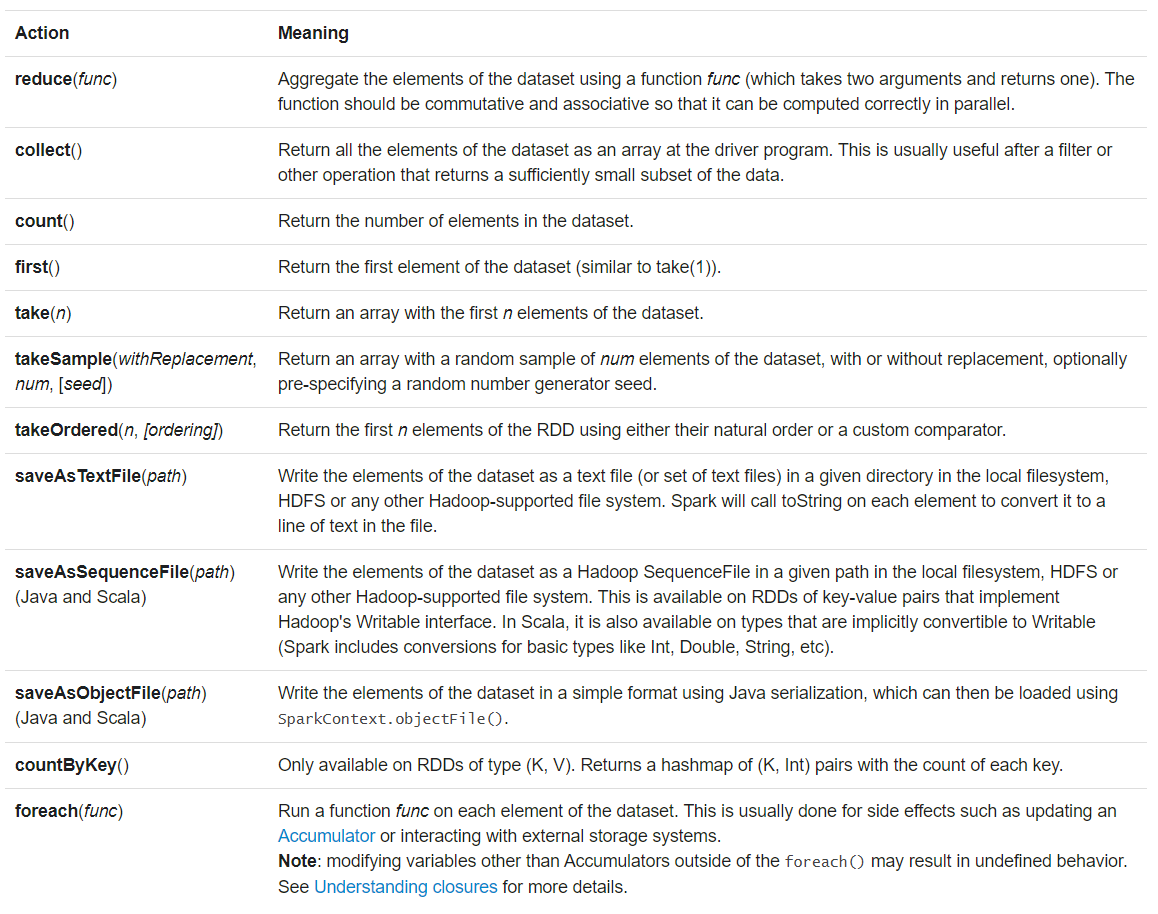
Spark暴露了一些动作的异步形式,如foreach()对应的foreachAsync()。调用后立即返回FutureAction,而不是阻塞直到完成。
7) shuffle
一种复杂且代价昂贵的操作,通常用于数据在节点间的再分区。
1‘ 背景
以reduceByKey为例,其将键名和所有具有相同键名的键值作为一个元组处理。但是这些键值通常分布在各个分区中。Spark中分区位置又与操作无关,因此需要读取所有分区的所有值,并将具有相同键名的键值汇聚到一起。
shuffle后的数据分区间的排序是确定的,但是分区内不确定。若要实现分区内排序,需要额外的操作:
- 使用mapPartition对各分区排序
- 使用repartitionAndSortWithinPartitions 在分区同时分区内排序
- 使用sortBy全局排序
常见的shuffle操作有再分区( repartition 和coalesce)、按键(计数除外,groupByKey和reduceByKey)和连接(cogroup and join)
2’ 性能影响
shuffle涉及到磁盘IO、序列化和网络IO,代价昂贵。
继承自MapReduce(与Spark的map()/reduce()没有直接联系),map任务负责组织数据,reduce任务负责聚合数据。在内部,map任务间结果保存在内存中(直到满溢),然后基于目标分区排序并写出到单个文件;reduce任务从排序的块中读取。
因为数据传输前后在内存中组织数据结构,shuffle占用大量堆内存。对于reduceByKey和aggregateByKey在map任务是创建数据结构(推荐原因,在map处已聚合),而其他ByKey操作在reduce任务处。当内存不足时,会引起额外的磁盘IO和垃圾回收。
同时,shuffle在磁盘上产生大量的中间文件。对于版本1.3,这些文件将保存到相应的RDD被回收。虽然可避免重算重复产生,但是如果长期引用或回收不及时,将消耗大量的磁盘空间。临时文件存储目录通过spark.local.dir配置。
可以通过修改配置减少shuffle损耗,详见Spark Configuration Guide中Shuffle Behavior一节。
(3) 持久化
为了快速计算和避免重算,利于迭代和快速交互,可以缓存数据集。
cache()仅存储到内存,persist()可以选择存储级别。
为了避免shuffle时节点失效引起的重算,Spark自动将某些中间数据缓存。

存储等级选择:
- 优先仅内存,除非空间不足。
- 内存空间不足时,使用内存序列化等级,选择合适的序列化库压缩
- 除非海量数据或重算代价很高,不选择磁盘等级
- 为了快速容错恢复,使用副本等级
Spark使用LRU算法自动移除缓存,或者使用unpersist()人为移除
5 共享变量
普通变量拷贝到执行节点后,变量变化不会与其他节点同步。
Spark提供两种共享变量:广播变量和累加器。
(1) 广播变量
广播变量是缓存在每个节点上的只读数据。
通常用于分发大量输入数据。
Spark自动将任务所需通用数据广播。这些数据以序列化形式缓存,并在任务执行前反序列化。因此,广播变量只在以下场景有用:多个阶段的任务需要同样的数据、数据需要以反序列化的形式缓存。
1 | scala> val broadcastVar = sc.broadcast(Array(1, 2, 3)) |
此外,广播变量中的对象v不应该再变动,为了保证所有节点获取到相同的数据。
(2) 累加器
累加器只能累加,可用于计数或加和。
Spark原生支持数值类型,其他类型需要人为实现。
阶段或任务中使用的累加器将在对应的WebUI中展示。
Spark通过SparkContext中对应的累加器方法创建不同数据类型的累加器。
任务调用add()方法加和,只能写,不能读。
驱动程序可以读取累加器值。
1 | scala> val accum = sc.longAccumulator("My Accumulator") |
通过AccumulatorV2实现自定义的累加器
1 | class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] { |
注意:Spark保证动作操作中,每个任务值更新累加器刚好一次,即使重启任务。而转换操作中,需要避免多次更新。
累加器不影响惰性计算。需要动作操作触发,才能实现转换操作中的累加器更新。
如下:
1 | val accum = sc.longAccumulator |
6 集群部署
详见 application submission guide
7 Java/Scala启动
使用Java将Spark作业作为子进程运行,详见org.apache.spark.launcher
8 单元测试
Spark支持常见的单元测试框架。
创建本地模式的SparkContext执行操作。
由于Spark不支持在同一项目中运行两个上下文,测试完成后,在finally语句块或框架teardown()方法中调用SparkContext.stop()终止。
9 学习指引
示例程序详见(Scala, Java, Python, R)
最佳实践详见 configuration和tuning
集群部署详见cluster mode overview
完整API详见Scala, Java, Python , R