注意:适用于版本3.4.9
1 定义
一种分布式协调服务。
实现了同步、配置维护、分组和命名服务,解决分布式应用的竞争和死锁问题。
易于编程,数据模型类似文件系统树状结构。
运行于Java平台并绑定在Java和C上。
设计目标:
简单
允许分布式进程通过类似标准文件系统的共享继承命名空间进行协调。命名空间包含多个数据注册器(znode),类似于目录与文件的关系。数据保存在内存中,可实现高吞吐量和低延迟。
重复
ZooKeeper在一系列主机间重复。这些主机称为ensemble。
组成ZooKeeper服务的服务器彼此知晓。共同维护内存中的状态映像和持久化存储中的事务日志、快照。只要大多数服务器可用,则ZooKeeper可用。
客户端与单一服务器保持TCP连接。发送请求、心跳,接收响应和查看事件(watch event)。连接中断,客户端连向另一台服务器
有序
每次事务都会被一个数字标记,可用于同步等的顺序判断。
快速
尤其适用于读多的场景,最佳读写比为10:1
2 快速入门
(1) 系统要求
Client: Java客户端库,应用程序用于连接ZooKeeper ensemble
Server: 运行ZooKeeper ensemble的Java服务端
Native Client: C语言实现的客户端,类似于Client
Contrib: 多种可选的附加组件
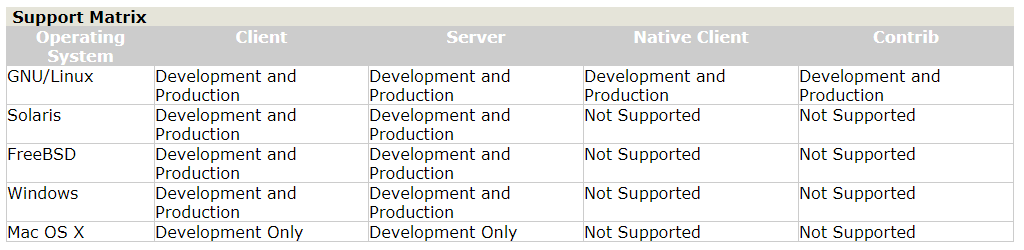
JDK 1.6及以上
ensemble: 至少3个服务器
(2) 集群配置
只要ensemble中大多数运行,服务即可用。推荐使用奇数个节点,如3-4个节点只能应对1个节点失效,而5个节点可以应用2个节点失效。此外需要注意外部资源引起的节点失效,如节点连接到同一个网络交换机等。
以下配置需应用于每一个节点:
1) 安装Java JDK。
2) 设置Java堆大小。避免swapping,影响性能。通常4GB机器设置为3GB。
3) 安装ZooKeeper。
4) 创建配置文件。可以任意命名,如使用以下配置开头:
1 | tickTime=2000 |
参数含义详见配置参数
5) myid文件
通过使用server.id=host:port:port配置使节点互相知晓。id通过dataDir目录下的myid文件定义。内容只包含1-255的一个数字。
6) 启动ZooKeeper
1 | java -cp zookeeper.jar:lib/slf4j-api-1.6.1.jar:lib/slf4j-log4j12-1.6.1.jar:lib/log4j-1.2.15.jar:conf \ org.apache.zookeeper.server.quorum.QuorumPeerMain zoo.cfg |
QuorumPeerMain启动ZooKeeper,用于通过命令行管理的JMX management beans被注册。细节详见ZooKeeper JMX document。
1 | 注意事项: |
查看bin/zkServer.sh脚本作为启动示例,其中有类似启动命令。
7) 测试部署
Java环境
1 | // 注意将IP替换为实际节点 |
3 配置参数
Zookeeper假定所有的服务器使用相同文件系统路径下的相同配置文件。
(1) 最小配置
clientPort:客户端连接端口。
dataDir:内存数据库快照,及事务日志(默认)。注意事务日志关系性能,受存放磁盘性能影响。
tickTime:ZooKeeper事件单位(毫秒)。用于约束心跳、超时等。如最小会话超时是两倍tickTime。
(2) 高级配置
以下带括号的属性可以通过Java系统属性的方式配置:
dataLogDir:单独指定事务日志目录,避免与快照竞争
globalOutstandingLimit(zookeeper.globalOutstandingLimit):限制客户端请求队列大小,避免内存溢出。默认1000
preAllocSize( zookeeper.preAllocSize):分配的事务日志块大小,默认64MB。当快照频繁时,适当降低块大小。
snapCount(zookeeper.snapCount):单个事务日志文件容量上限,超出后新建一个文件。默认100,000
maxClientCnxns:套接字层面上单个IP地址并发连接上限。默认60。0表示不限。
clientPortAddress:接收客户端请求的主机接口。默认连接到服务器clientPort
minSessionTimeout:最小会话超时。默认2倍tickTime
maxSessionTimeout:最大会话超时。默认20倍tickTime
fsync.warningthresholdms(zookeeper.fsync.warningthresholdms):fsync告警时间,否则在事务日志中输出告警信息。默认1000ms,只能通过Java系统属性配置。
autopurge.snapRetainCount:保留的最近的快照和事务日志数量,删除之前的。默认3,最小3。
autopurge.purgeInterval:autopurge触发时间间隔,默认0, 单位小时。
syncEnabled(zookeeper.observer.syncEnabled):The observers now log transaction and write snapshot to disk by default like the participants. This reduces the recovery time of the observers on restart. 默认true
(3) 集群选项
electionAlg:选举算法。默认3,其中0-2标记为弃用,3 统一称为FastLeaderElection
- 0 :原始基于UDP的版本
- 1:非认证UDP版本
- 2: 认证UDP版本
- 3:TCP版本
initLimit:follower与leader连接、同步的tickTime倍数。当数据量大时适当增加。
leaderServes(zookeeper.leaderServes):是否允许客户端连接leader,默认yes。当有三个以上服务器时,建议开启leader选举。
server.x=[hostname]:nnnnn[:nnnnn]:集群成员。当服务器启动时通过myid文件判断自身身份。id在文件和配置中必须匹配。nnnnn代表端口,前者用于服务器与leader通信,后者用于在electionAlg为1-3时选举。
syncLimit:允许follower与leader同步的tickTime倍数。长时间断开,将会下线。
group.x=n[:n]:启用层次结构。x为小组识别号,右侧为冒号分隔的服务器id.详见hierarchical quorums
weight.x=nn:与group合用。表示主机在选举和原子广播协议中的权重。默认1。

cnxTimeout(zookeeper.cnxTimeout):leader选举通知的开放连接超时。只对electionAlg为3时有效,默认为5s。
(4) 认证与授权选项
zookeeper.DigestAuthenticationProvider.superDigest( zookeeper.DigestAuthenticationProvider.superDigest):允许管理员以超级用户身份访问znode层次结构,不再进行ACL检查。org.apache.zookeeper.server.auth.DigestAuthenticationProvider可用于更新值,使用一个super:<password>参数调用。当服务器启动时,提供系统属性值super:<data>作为更新值。当从client认证时,传入一个模式digest和认证数据super:<password>。注意:由于明文传递,需要谨慎。
isro:测试是否只读。ro表示只读,rw表示非只读。
gtmk:以64位有符号十进制长整型格式返回当前trace mask。
stmk:设置64位trace mask。每一位表示开启或关闭特定的目录。为了查看日志消息,Log4J必须启用TRACE等级。默认0b0100110010
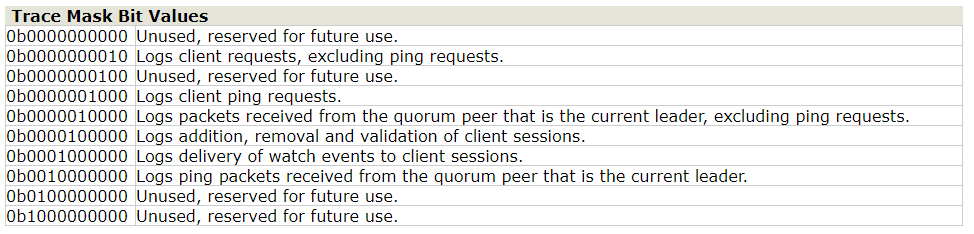
1 | $ perl -e "print 'stmk', pack('q>', 0b0011111010)" | nc localhost 2181 |
以上使用Perl的Pack功能生成大端表示的掩码,通过netcat发送给服务器。服务器返回十进制表示。
(5) 实验选项/特性
Read Only Mode Server(readonlymode.enabled):客户端只读,不可写,不能看见其他客户端的变化。默认关闭。详见ZOOKEEPER-784 。
(6) 不安全选项
forceSync(zookeeper.forceSync):关闭后不再请求同步更新到事务日志。
jute.maxbuffer(jute.maxbuffer):znode存储的数据量上限。单位KB,默认0xfffff,即1MB。只能设置为Java系统属性,要求所有服务端和客户端设置,否则报错。
skipACL(zookeeper.skipACL):跳过ACL检查。可增加吞吐量,但完全暴露了数据树。
quorumListenOnAllIPs:接收所有合法IP的连接。影响ZAB协议和快速选举协议的连接。默认false。
(7) 使用Netty框架通信
Netty是基于NIO的客户端、服务器通信框架。相比直接使用NIO,其简化了网络层面的连接。此外,Netty支持加密(SSL)和身份认证(证书)。ZooKeeper默认直接使用NIO,从版本3.4开始可以选用Netty。通过设置zookeeper.serverCnxnFactory为org.apache.zookeeper.server.NettyServerCnxnFactory,可以对客户端和服务器分别设置。
参考资料
ZooKeeper Getting Started Guide
ZooKeeper Administrator’s Guide
Howto Setup Apache Zookeeper Cluster on Multiple Nodes in Linux